【论文笔记】FFB6D
一、概述
该方法认为RGB图像和深度信息是两个数据源,关键在于如何使两者有机结合。
Our key insight is that appearance information in the RGB image and geometry information from the depth image are two complementary data sources, and it still remains unknown how to fully leverage them.
通过在RGB和深度信息的特征提取网络的每一层中建立双向融合通道,这样两个网络可以使用另一个网络的局部和全局特征。
Specifically, at the representation learning stage, we build bidirectional fusion modules in the full flow of the two networks, where fusion is applied to each encoding and decoding layer . In this way, the two networks can leverage local and global complementary information from the other one to obtain better representations.
在网络输出层,设计了考虑纹理和几何信息的关键点选取算法,简化了关键点定位,实现了精确的位姿估计。
Moreover , at the output representation stage, we designed a simple but effective 3D keypoints selection algorithm considering the texture and geometry information of objects, which simplifies keypoint localization for precise pose estimation.
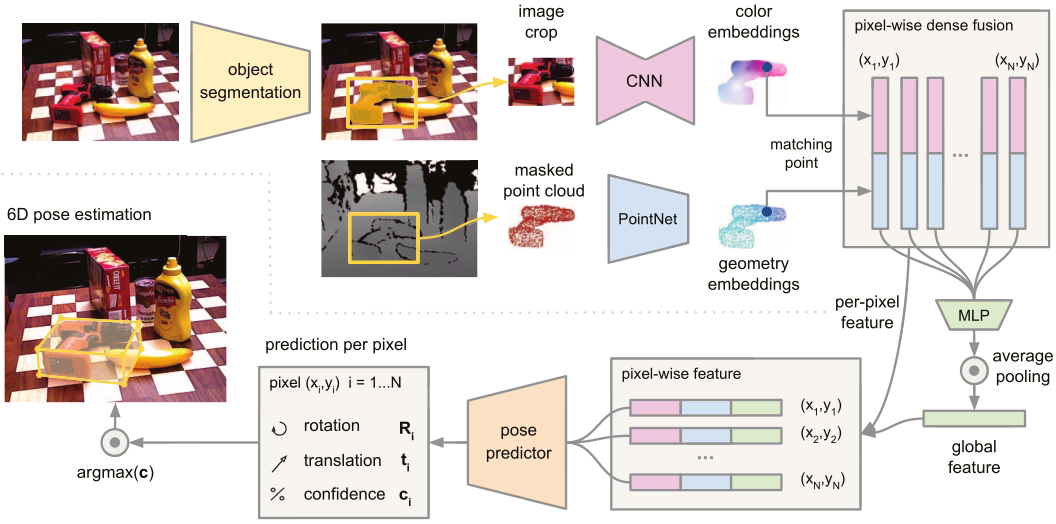
二、FFB6D的流程框图
整体流程
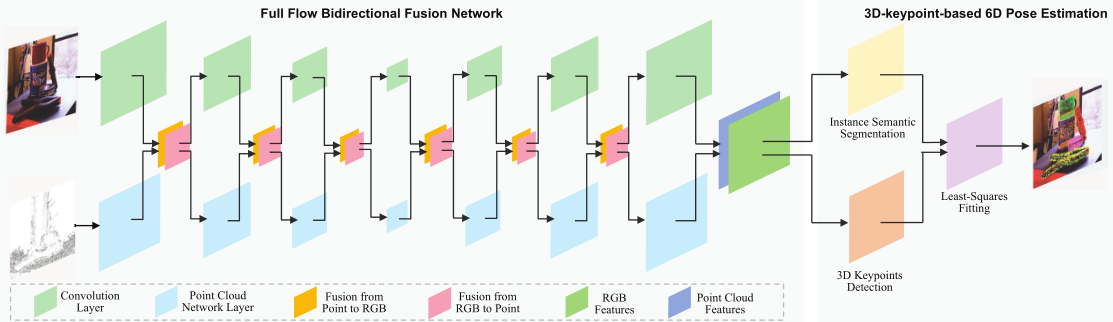
利用CNN和点云网络分别对RGB和点云进行表示,两个网络的每一层之间通过双向融合模块搭建桥梁。最终提取的逐点特征被送入实例分割模块和3D关键点投票模块,最终回归出物体的6D位姿。
像素->点云融合模块
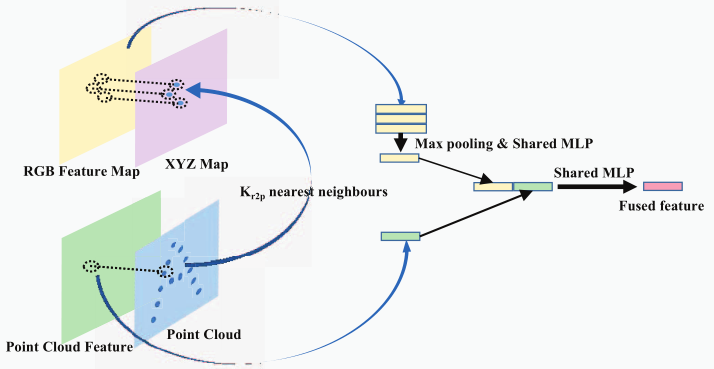
RGB特征图部分:对于每一个点云,找到它的空间最近邻点,搜索这些点对应的RGB特征图,通过池化和共享多层感知机将这些特征图生成为一个RGB特征图。
点云特征部分:直接提取点云特征。
两者组合成为一组新的RGB-点云特征,交给下一层进行处理。
点云->像素融合模块
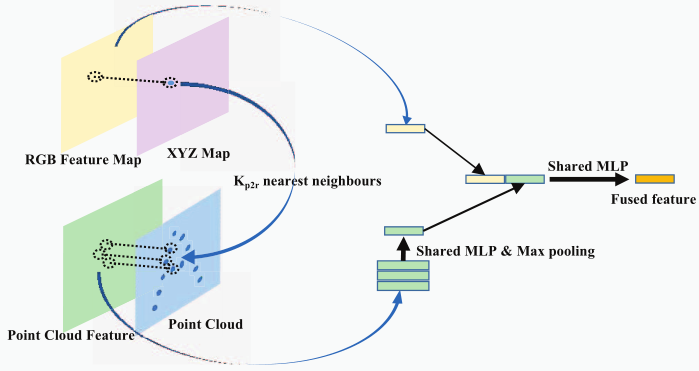
与像素->点云为对偶处理方式。
三、具体实现
3.1 总体流程
- 逐点提取RGBD特征,用于每个物体的3D关键点定位
- CNN网络提取RGB特征
- Point Cloud Net提取点云特征
- 两者双向融合
- 将逐点特征输入到实例分割网络和3D关键点检测模块,提取每个物体的3D关键点
- 用最小二乘法拟合姿态参数
3.2 双向融合网络
Full Flow Bidirectional Fusion Network
在特征提取前首先用相机标定矩阵将深度图转换为点云图。
网络基本框架是分别用CNN和PCN网络对RGB和点云进行特征提取,并在两个网络之间添加双向通信模块。
(1)像素->点云融合 Pixel-to-point fusion
常规方法是从RGB图中生成图像的全局特征,添加到每一个,但这种方法会引入背景和其他物体的特征,对结果反而造成干扰。
本文所使用的方法为:
- 接受RGBD特征图,对于点云特征图中每一个点云
- 找到其在XYZ空间对应的点,以及周围的最近邻点
- 找到这些点对应的RGB特征
- 将这些RGB特征通过最大池化和多层感知机压缩到一个通道中
- 把一个点云特征和一个压缩好的图像特征串联组合成一组RGBD特征向量
- 同样方法计算所有点的RGBD特征向量,组成传递RGBD特征图给下一层
注意:由于随深度的增加,特征图的尺寸将会减小,需要采取方法使每一个特征图像素能找到它对应的3D点云坐标。本文采取的方式是在最近邻搜索算法中也使用同样步长的卷积核进行卷积,这样图像特征图和点云特征图就可以对应了。(不将整个点云特征进行同样的卷积是为了避免前景背景深度大幅度变化导致的卷积噪声)
(2)点云->像素融合 Point-to-pixel fusion
与像素->点云融合类似
- 接受RGBD特征图,对于RGB特征图中每一个像素
- 找到其在XYZ空间对应的点,以及周围的最近邻点
- 找到这些点对应的点云特征
- 将这些点云特征通过最大池化和多层感知机压缩到一个通道中
- 把一个RGB特征和一个压缩好的点云特征串联组合成一组RGBD特征向量
- 同样方法计算所有点的RGBD特征向量,组成传递RGBD特征图给下一层
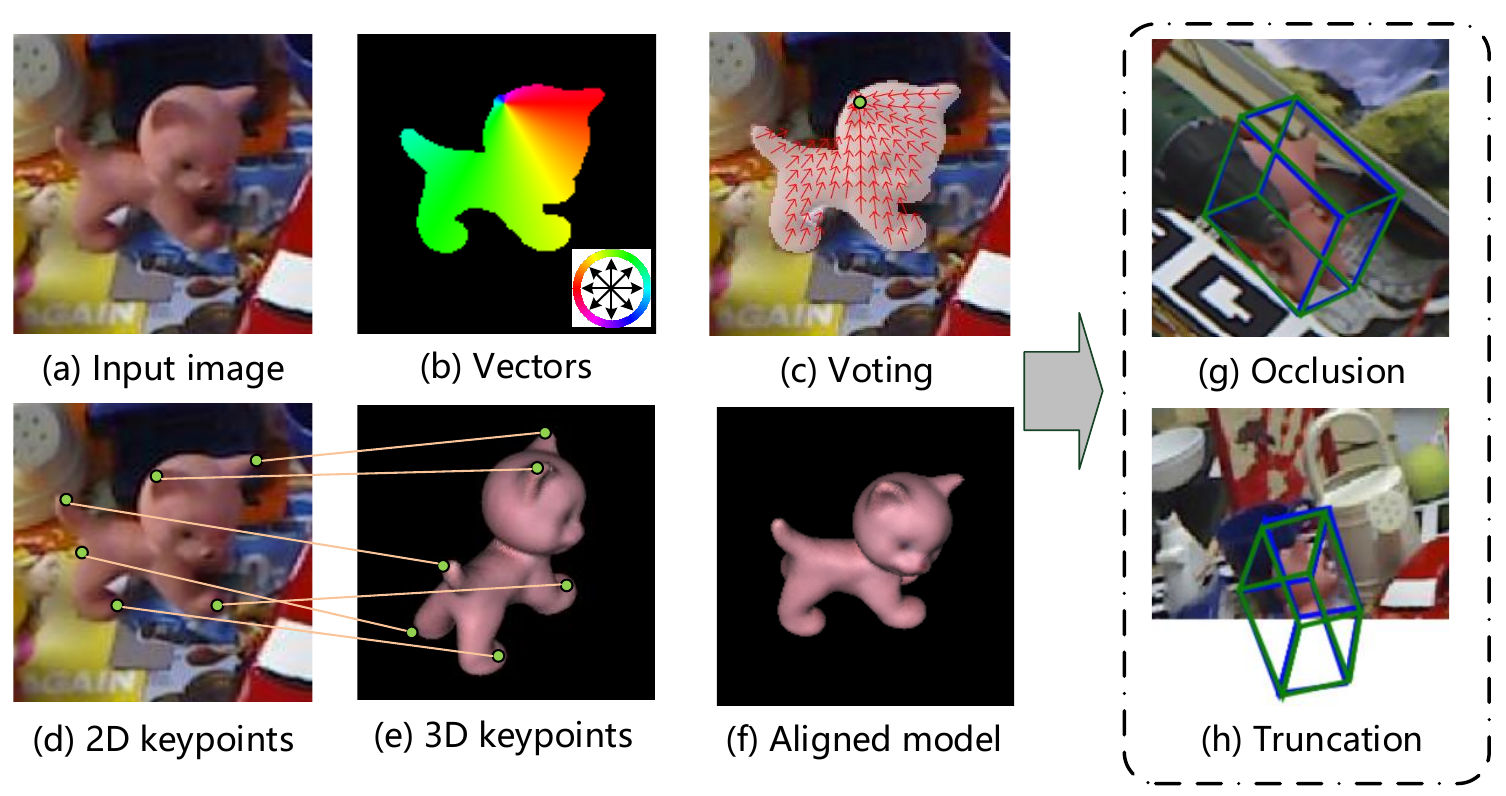
3.3 基于3D关键点的6D位姿估计
该部分延续了PVN3D的3D关键点算法,进行了优化使算法能够充分利用图像和纹理信息。
(1)逐对象的3D关键点检测
通过实例语义分割模块来区分不同的对象,包括语义分割和中心点投票两个子模块。
- 前者用于预测每个点的语义标签
- 后者计算每个点到对象中心的距离。
通过添加关键点投票模块来恢复每个对象的3D关键点。学习选定的关键点(利用MeanShift聚类方式)的逐点偏移来实现。
(2)关键点选择
以前的方法是在物体表面通过最远点采样算法FPS,首先确定一组随机点,然后再物体表面逐个找到FPS最远点并加入到序列中,直到点数量到达N。
这种方法有时会随机到没有特征的平坦表面,得到的关键点反而没有特征。
本文提出了SIFT-FPS方法,通过在二维平面中用SIFT算法找到特征点,作为初始序列,然后使用FPS找到N个关键点。
(3)最小二乘拟合
上面计算的是物体坐标系的3D关键点,即每个关键点相对于物体中心的偏移量。
我们又有相机中每个点的3D关键点对应的点云坐标。
通过最小二乘拟合我们就可以计算物体的位姿了。
3.4 网络体系
RGB:使用ImageNet预训练的ResNet34作为RGB的编码器,使用PSPNet作为解码器
PointCloud:从深度图中抽取了12288个点,使用RandLA-Net进行学习。
上述两个网络的编解码层,利用最大池化和共享MLP构建双向融合模块。
常规优化:语义分割分支使用Focal Loss,中心点投票和3D关键点投票使用L1 Loss。
SIFT-FPS:将目标物体放在球体的中心,并等距采样摄像机的视点,通过渲染引擎获得带有相机姿态的RGBD图像,然后使用SIFT检测2D关键点,并转换到3D,在转换为相机坐标系。
(应该是使用mesh模型获取RGBD图像和关键点)
总结
相比于DenseFusion,我认为FFB6D通过一些rgb工作做了很有用的改进。
首先DenseFusion是利用CNN和PCN单独提取RGB和点云的特征,再加上全局特征,三者合并组合成一个点的特征,然后进行姿态预测。
而FFB6D相当于在特征提取阶段就将RGB和点云信息进行了融合,然后进行实例分割和关键点检测。
用不恰当的比喻,类比到2D图像识别中:
DenseFusion是从用一个网络提取每个点的X方向特征,再用一个网络提取每个点的Y方向特征,在提取整张图的全局特征,三者串在一起就是一个点的特征向量,用这个特征向量再进行回归计算。
FFB6D是在每一个点上,在一个网络中每层都同时看X方向和Y方向的特征,得到的也是两者组合的特征。
特征的含义:同样类比与二维图像识别,例如人脸识别,前几层每个特征图提取的是局部特征,例如边界线,角点,中间几层特征图得到的是部分特征,例如嘴角,眼睛,鼻子等,最后几层特征图得到的是整体特征,每个特征图中基本都包含一个人脸。此处也类似,使用点特征也就对应二维的像素,前几层提取的是局部特征,就是物体的边、角等,最后几层特征图就会代表物体整体。
问题
既然有RGB卷积网络,为什么不能有4通道卷积,类比于图像处理,直接将RGBD通过一个卷积核得到一个数字,将D也作为一个通道,这样是否有效?
代码复现
1 安装
1.1 准备工作
1 | git clone https://github.com/ethnhe/FFB6D.git |
1.2 环境搭建
创建虚拟环境(据说3.6可以正常使用,3.8无法成功)
1 | conda create -n ffb6d python=3.6 |
修改requirement.txt,将yaml改为pyyaml,删除pprint和glumpy,并在最后添加下面这些包
1 | tqdm |
然后安装依赖
1 | pip3 install -r requirement.txt |
安装apex
1 | git clone https://github.com/NVIDIA/apex |
如果出现
python setup.py egg_info Check the logs for full command output的错误
使用python setup.py install -v安装
安装normalSpeed
1 | git clone https://github.com/hfutcgncas/normalSpeed.git |
安装tkinter
1 | sudo apt install python3-tk |
编译RandLA-Net
1 | cd ffb6d/models/RandLA/ |
2 数据准备
3 训练、评估与可视化
4 自己的数据集
4.1 生成mesh信息
(1)安装raster_triangle进行RGBD图像渲染
1 | git clone https://github.com/ethnhe/raster_triangle.git |
如果出现
fatal error: opencv2/highgui/highgui.hpp: No such file or directory
修改rastertriangle_so.sh文件中-I部分为-I /usr/include/opencv4修改后如下:
g++ rastertriangle_so.cpp -o rastertriangle_so.so -shared -fPIC -Wall -I /usr/include/opencv4 -L/usr/lib/x86_64-linux-gnu -lopencv_stitching -lopencv_objdetect -lopencv_superres -lopencv_videostab -lopencv_calib3d -lopencv_features2d -lopencv_highgui -lopencv_video -lopencv_photo -lopencv_ml -lopencv_imgproc -lopencv_flann -lopencv_core
(2)编译FPS脚本
1 | cd ffb6d/utils/dataset_tools/fps/ |
(3)安装python依赖
1 | pip3 install -r requirement.txt |
(4)生成物体的信息,如半径、3D关键点等
1 | python3 gen_obj_info.py --help |
如果使用ply模型,并且角点颜色信息包含在ply模型中,可以使用默认raster triangle来渲染。
1 | # 以ape物体为例 |
如果使用obj模型,可以将每一个角点转换为米为单位,然后使用pyrender。
1 | # 以cracker box物体为例 |
bug:需要python3.8
4.2 修改数据集信息
先将FFB6D/ffb6d/common.py文件复制备份一个。
然后修改FFB6D/ffb6d/common.py文件内容。
4.3 编写数据集预处理脚本
参考FFB6D/ffb6d/datasets/ycb/ycb_dataset.py,注意要正确修改调用模型信息的函数,例如3D关键点、中心点、半径等。
4.4 检查数据集预处理情况(非常重要)
通过可视化检查是否正确处理了数据,例如投影的关键点、中心点、每个点的语义标签等是否正确。
例如可以运行python3 -m datasets.ycb.ycb_dataset来可视化投影的中心点和所选的关键点。
4.5 确保数据能被正确加载
检查FFB6D/ffb6d/utils/pvn3d_eval_utils.py中能否正确在物体坐标系中加载关键点、中心点、半径等信息。
4.6 检查所有设置是否正确
利用ground_truth数据进行评估,检查所有设置是否正确,如果正确,结果应该接近100。
例如将-test_gt参数传给train_ycb.py,就可以获得YCB数据集的ground_truth结果。
1 | tst_mdl=train_log/ycb/checkpoints/FFB6D_best.pth.tar |
 微信支付
微信支付 支付宝
支付宝