【论文笔记】面向非结构化环境的机器人6D抓取技术研究
针对非结构化环境中抓取物体的问题,从以下四个方面展开研究,并在相关开源算法的基础上进行改进。
- 实例分割(SOLOv2)
- 位姿估计(Contact-GraspNet)
- 地图构建(Otomap)
- 运动规划(GRRT-Connect)
一、研究现状
2.1 物体识别与位姿估计
物体识别:
- 两阶段方法:RCNN
- 单阶段方法:YOLO,SSD
位姿估计:
- 基于点对应
- 基于投票
- 基于回归
代表性工作:
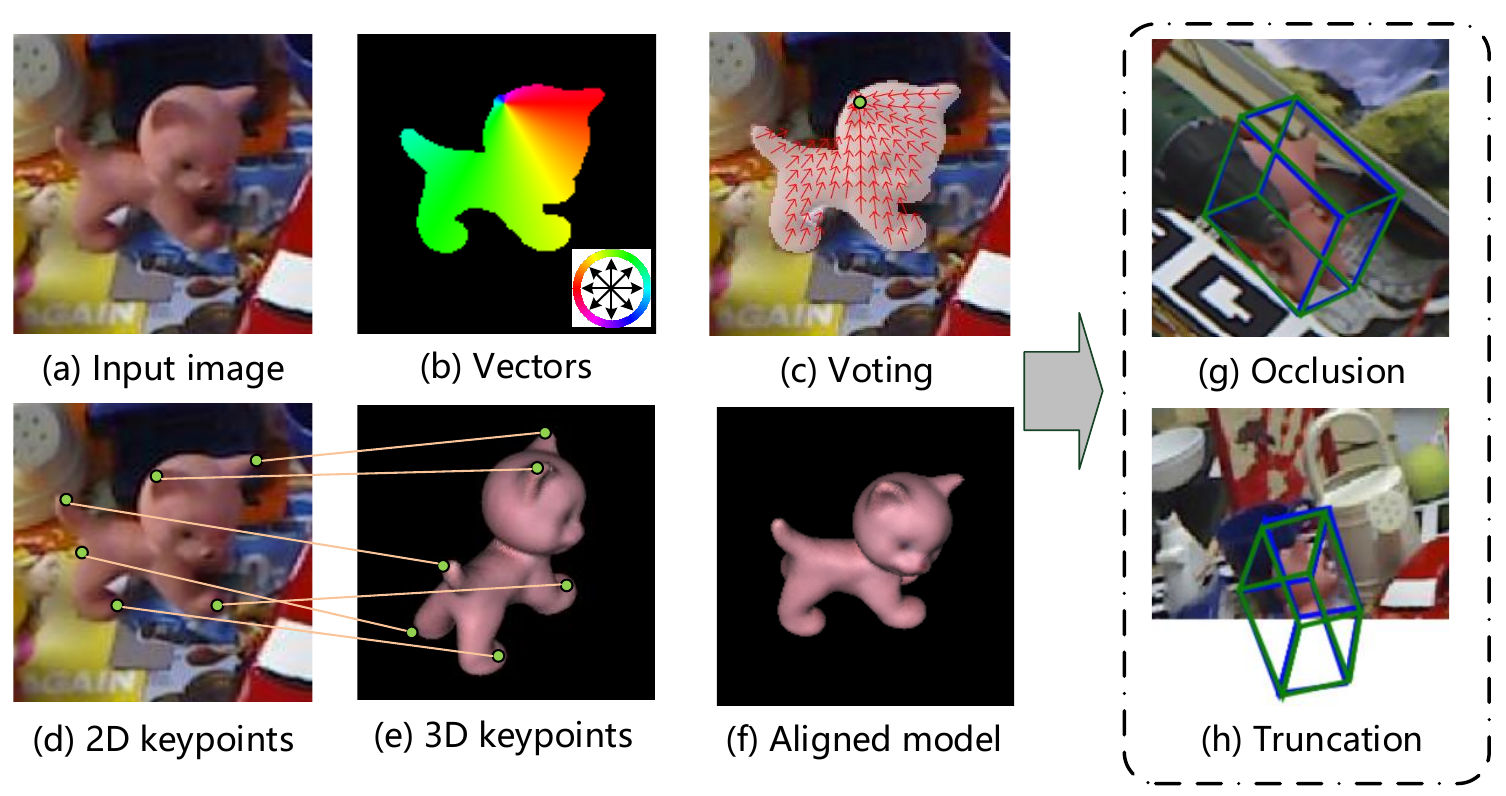
- PoseCNN:三个分支完成语义分割,位置预测(霍夫投票)、姿态预测(池化+回归)
- 6-PACK:使用立方体包络框表示物体,引入anchor机制,无需三维模型
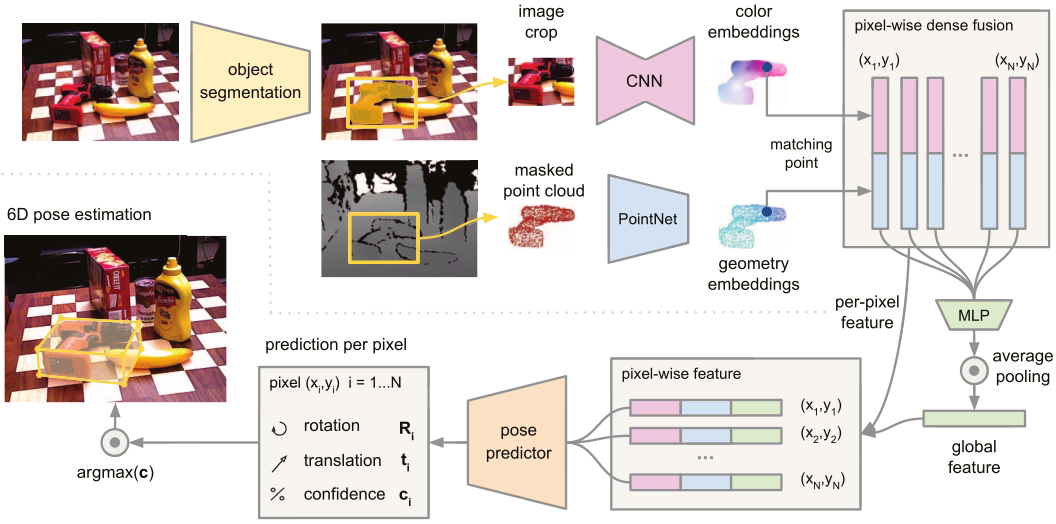
- DenseFusion:RGB和点云融合,实现端到端的训练
什么是霍夫投票?
为什么anchor机制可以无需三维模型估计位姿?
2.2 端到端的抓取估计
代表性工作:
- GQ-CNN:抓取采样(获得多个候选抓取配置),质量评估
- GPD:不需要分割对象
- PointNetGPD:对局部结构进行特征提取和表征
- RegNet:抓取点置信度预测网络+抓取区域生成网络+抓取校正网络
二、基于SOLOv2的目标识别及分割
2.1 实例分割算法简介
实力分割可以按以下方式分类:
- 两阶段方法
- 自顶向下:先确定物体所在区域,再在区域内进行语义分割
- 自底向上:先进性像素级别的语义分割,再学习区分不同实例
- 单阶段方法
相关算法
- Mask RCNN:分成目标检测分支和mask预测分支实现
- Yolact:分为生成原型掩膜和生成掩膜系数两个字任务并行运行
- PolarMask:将实力分割和目标检测任务采用相同的建模方式
- BlendMask:融合实例级注意力信息和低级别语义信息改进掩码预测
2.2 SOLOv2
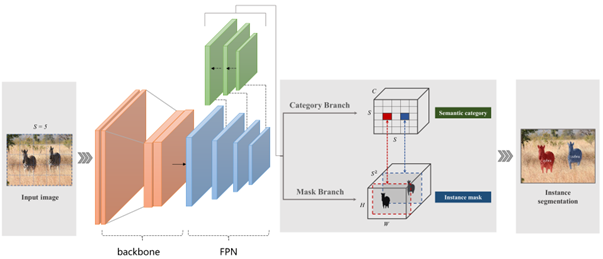
SOLOv2是,无候选框,单阶段的实例分割算法。
2.2.1 网络结构
SOLOv1的网络结构
- backbone:通过卷积、池化、残差网络、激活函数等单元对图像特征进行提取,采用ResNet50或ResNet101
- FPN网络:建立特征金字塔,将低层特征和高层特征进行融合
- SOLO head:分为两个分支,类别预测分支和掩膜预测分支。类别预测分支输出的维度是SxSxC,特征图被分为SxS网格,每个通道表示物体属于某一类别的置信度。掩膜预测分支输出HxWxS^2的特征图,H和W为特征图的高和宽,通道数S^2为可以预测的最大掩膜数量。
SOLOv2网络结构改进
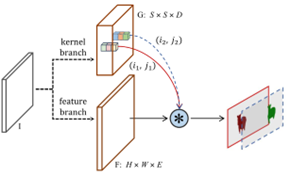
- 掩膜预测分支使用Decoupled SOLO结构进行改进,将通道数由S^2将为2S。
- 提出了动态预测掩膜的方法,将掩膜预测分支划分为卷积核预测分支和掩膜特征预测分支,掩膜通过卷积核和掩膜特征图卷积得到。
2.2.2 非极大值抑制算法
非极大值抑制算法NMS,主要作用是筛选出局部极大值,抑制非极大值,通过NMS算法可以筛选出得分最高的检测框。
Soft NMS算法通过引入置信度防止两个目标接近情况下其中一个检测框被抑制的情况。
Matrix NMS算法,使用矩阵并行运算极大提高了算法运行速度,可以在1ms内处理500个mask。
一个预测的掩膜$m_j$被抑制的因素归为两方面:
- 每个预测的掩膜$m_i$对$m_j$的惩罚
- $m_i$本身被抑制的概率
如果$m_i$被抑制,那么它对$m_j$的惩罚将不存在。而$m_i$被抑制的概率与掩膜之间的交并比IOU最大值正相关。
2.2.3 正负样本分配策略和损失函数设计
目标检测算法采用的正负样本分配策略通常是当网格落入任何物体的真实中心区域,那么就将其视为正样本,反之则为负样本,通过实验验证这种设计通常是最有效的。SOLOv2算法采用类似的策略。
物体的真实区域设置为S,S为以掩膜中心位置$(c_x, c_y)$为中心,宽高为$(\epsilon w, \epsilon h)$的矩形区域,其中$\epsilon=0.2$,$w, h$为真是淹没的宽高
$S=(c_x, c_y, \epsilon w, \epsilon h)$
若网格$(i, j)$落在任何物体的真是区域中,就可以将类别预测分支的该位置和掩膜预测分支的对应通道设置为正样本,反之为负样本。
2.2.4 图像增广
图像增广技术可以分为在线增广和离线增广。在线增广即在模型训练过程中同时使用图像增广技术,在图像输入模型前对其进行增广。离线增广技术是在模型训练之前就对数据进行增广。
(1)图像增广技术
- 旋转和裁剪,通过翻转和裁剪可以有效降低模型对物体位置的依赖性;
- 亮度和色彩变换,可以有效降低模型对色彩、光照的敏感程度;
- 噪点引入,可以增强模型对图像噪声的抗干扰性;其他常见的技术还有锐化、对比度增强、仿射变换等等。

(2)应对遮挡
本项目引入了两项应对遮挡的图像增广技术,分别是Cutout和GridMask。
Cutout就是模拟遮挡情况,实现方法是在图像中随机选取一块方形区域,采用全0或其他纯色值填充,通过实验验证Cutout可以较好地提升模型的泛化能力。
GridMask是在Cutout的基础上进行改进,因为Cutout的方形区域时随机的,因此可能会出现对重要特征全部遮盖的情况,GridMask采用排列的正方形区域进行掩码,实现对特定区域信息的dropout。

(3)迁移学习
本项目中通过使用在coco数据集中预训练的网络参数进行迁移,迁移至实验数据集中进行训练,模型可以基于COCO数据集学习到大量特征,具备极强的泛化能力,经过较短时间的训练即在本文数据集上达到预期的精度。
三、抓取估计
3.1 任务分析
输入:
RGB-D 图像
已有:
SOLOv2得到的物体语义信息和位置
问题:
获取目标物体的6D数据,并计算抓取位姿
6D抓取估计方法:
- 基于已知模型的方法
- 过程:先进性物体位姿估计,再进行抓取匹配
- 优点:直接从数据库中搜索对应的模型和抓取,速度快,精度高
- 缺点:无法对未知物体进行抓取,准确性依赖于物体位姿估计的结果
- 基于无模型的方法
- 过程:端到端,从点云数据直接生成抓取预测,并进行抓取评估
- 缺点:需要大量数据训练来提高鲁棒性和精度
3.2 抓取生成网络
使用基于PointNet改进的分层级点云处理网络,进行点云特征提取和分割。由前半部分的分层级特征提取网络和后半部分的全连接分类网络或上采样分割网络组成。
(1)网络基础
分层级特征提取网络:
- 采样层:对点云使用FPS算法进行降采样,减少计算负荷
- 组合层:以采样的C1为中心,在初始点云C中寻找K个邻域点,以覆盖点云的局部特征
- 特征提取层:通过小型PointClond层提取点云组的特征
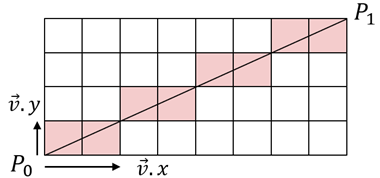
FPS算法:先在初始点云C中随机选取一点p0,将其加入到集合C1中,然后计算C中所有点与P0的距离,选择距离最远的作为p1,将其添加到集合中,以此往复。
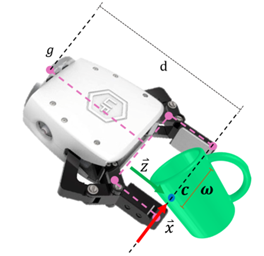
将采样得到的点作为抓取接触点,抓取位姿$[R_g,t_g]$定义如下
$t_g=c+\frac{w}{2}-dz$
$R_g=[x, x\times z, z]$
c——即夹爪闭合时和物体的接触点;
x——二指夹爪的平行钳口方向( 轴), ;
z——夹爪接近物体的方向( 轴), ;
w——夹爪抓取的宽度;
d——夹爪的长度;
(2)网络结构
Contact-GraspNet网络结构由PointNet++主干网络和四个分支预测网络组成。
网络的输入为单视角点云、彩色图、深度图。
四个分支网络分别用于预测抓取方向Grasp_x、抓取方向Grasp_z,抓取预测分数Score、抓取宽度Width。
总体流程如下:
- 输入:从场景点云中选取20000个点作为网络输入
- PointNet++:降采样得到2048个抓取接触点,提取得到特征
- 预测分支:将特征输入,获得x、z方向预测、抓取分数和抓取宽度
- 汇总:将所有分支输出与接触点联合计算得到抓取集合
四、运动规划
4.1 基于Octomap的规划地图构建
Octomap八叉树地图是机械臂运动规划、SLAM领域复杂地图构建的最佳方式之一。
Octomap的底层数据结构是Octree八叉树,以Octree表示层级结构。三维空间可以分为8个象限,每个子象限又可以分为8个象限,只要未达到最大递归深度就可以一直划分。
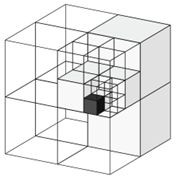
Octomap将空间划分为三维体素网格,每一个体素有两种状态,free自由用0表示,occupied被占据用1表示。根据点云观测数据确定体素是否被占据,通过使用Ray-Casting算法,以相机光心为起点,点云中每个点为终点,形成一组射线,射线经过的体素就是非占据free状态。
深度图修复
使用RGB-D相机采集的深度图在物体的边界存在空洞缺陷,通过双滤波核修复算法可以有效填充物体边界的空洞区域。
原理:遍历深度图所有像素,当出现像素值为0(空洞)时,统计以其为中心,滤波核大小范围内不为0的像素值及出现频率,选择出现最多的替代当前像素。
双滤波核:先对小空洞区域使用小滤波核3x3修复,例如边缘部分;对于大空洞区域使用大滤波核5x5修复,减少误差。
4.2 基于GRRT-Connect的机器人运动规划算法
(1)概述
运动规划算法主要分为两类:
- 基于图搜索
- 原理:将空间用离散状态进行表示
- 优点:可以寻找出最优解
- 缺点:计算代价较大
- 算法:Dijkstra算法、A*算法
- 基于随机采样
- 原理:对状态空间进行随机采样
- 优点:可以直接在构形空间进行规划,将动力学约束考虑在内
- 缺点:存在概率非完备或规划非最优问题
- 算法:快速扩展随机树RRT系列算法、概率路径图PRM系列算法、ABIT*算法、BIT*算法
(2)RRT算法原理
RRT
快速扩展随机数算法的核心思想就是通过随机采样探索未知空间,利用树形结构维护已知状态节点。
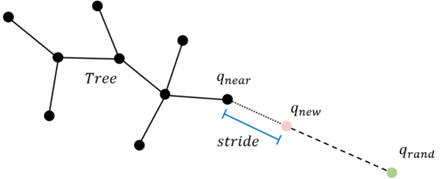
RRT算法随机生成采样点 $q_{rand}$,然后遍历树中的节点找到离$q_{rand}$最近的节点${q_{near}}$ ,以$q_{near}$为起点向$q_{ramd}$方向生长stride的距离得到一个新的节点$q_{new}$ ,如果$q_{near}$和$q_{new}$的连线不会与状态空间中的障碍物发生碰撞,就将连线和节点$q_{new}$加入扩展树,重复这个过程。
RRT-Connect
通过双树同时对空间进行探索,一棵以起始点为根节点进行生长,另一棵以目标点为根节点进行生长。当两棵树连接到一起时,路径搜索完成。
GRRT-Connect
贪婪式快速扩展随机树算法主要通过两个方法进行优化:
- 贪婪式步长递增:如果不发生碰撞,随机树一直往目标节点生长。并引入补偿增长因子$g_{rate}$,每生长一个节点就将步长stride乘以$g_{rate}$,如果与障碍物发生碰撞,则将步长stride回归到初始值,通过这种步长倍增的方式可以加快节点的连接速度并减少节点的产生。
- 贪婪式二分剪枝策略:每次迭代尝试将当前节点与目标节点相连,如果不予障碍物发生碰撞则删除两者之间的节点,进行剪枝。否则采用二分法将目标点设置成两者中间路径上的节点,重复过程知道目标点与当前点相邻。
 微信支付
微信支付 支付宝
支付宝