【论文笔记】DenseFusion
标题:DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
作者团队:斯坦福大学(李飞飞)
期刊会议:CVPR
时间:2019
代码:https://sites.google.com/view/densefusion/
介绍
以前的位姿估计工作,要么单独提取RGB和深度图,要么使用了昂贵的后处理过程,例如posecnn,这使得算法在聚集场景的应用与实时性受到了很大的限制。
本文提出了一种异形架构,对两个数据源(RGB和深度图)进行分别处理,并用一种新型的dense fusion network提取像素级稠密特征,从中估计姿态。
此外本文还提出了一种端到端的姿态优化步骤,进一步改善了估计过程,可以实现接近实时的判断。
模型
本文的模型是为了从一系列RGBD图像中估计物体的6D位姿。为了不丧失一般性,6D位姿使用齐次变换矩阵表示,即旋转矩阵$R\in SO(3)$和平移矩阵$T\in \mathbb R^3$。并且,由于物体的6D位姿来自相机,因此结果都是相对相机参考系。
本文的关键是如何从不同的两种数据(RGB和深度图)中提取特征,并进行适当的融合。
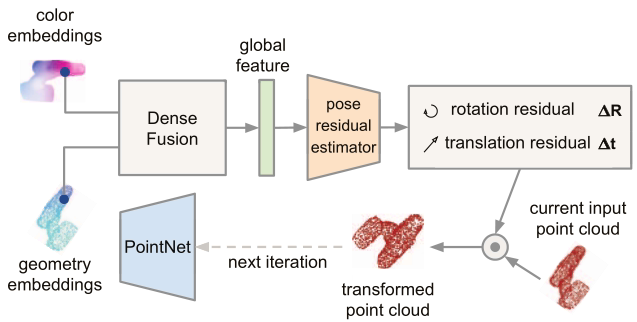
总体架构
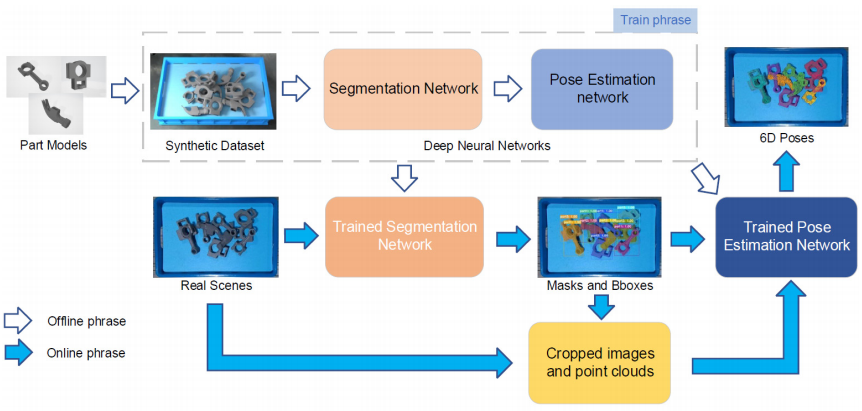
总体架构主要分为两个阶段:
- 第一阶段:对RGB图进行语义分割,分割出所有已知的目标物体。然后将掩码对应的图像,以及深度像素送入第二阶段。
- 第二阶段:加工分割的结果,并估计物体的6D位姿。该阶段包含以下组件
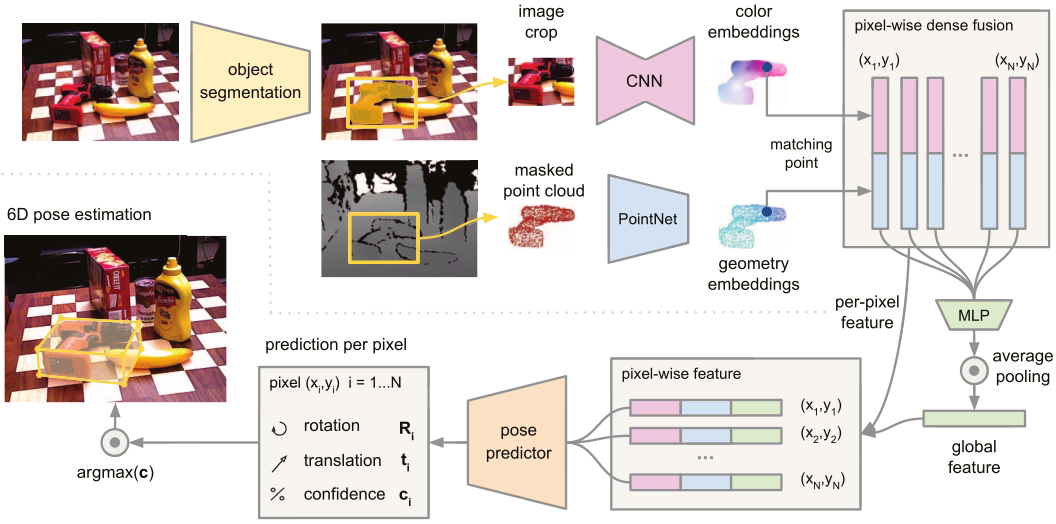
- 一个全卷积网络,处理颜色信息,并将裁减的图像中每个像素映射到一个颜色特征向量
- 一个基于PointNet的点云处理网络,将掩码对应的点云处理为一个几何特征向量
- 一个融合上面两个特征向量的像素级融合网络,并基于无监督置信度评分输出物体的6D位姿估计
- 一种迭代自优化方法,以学习的方式训练网络并迭代优化估计结果
语义分割
语义分割网络,将图像作为输入,生成一个N+1通道的语义分割图(背景+N个物体分类),每个通道都是二维掩码。
本文使用的是现有的语义分割架构,由PoseCNN所提出的语义分割分支。
稠密特征提取
对于颜色信息和深度信息,本文分别单独处理它们,从特征向量中获得颜色和几何特征。
(1)稠密3D点云特征
以往方法通常将深度信息作为图像的额外通道进行处理,但这样会忽视隐含在深度通道的3D结构信息。因此本文将掩码分割出的深度像素转换为点云,然后使用类PointNet结构提取几何特征。
PointNet将原始点云作为输入,然后学习将每个点附近的信息和点云作为整体进行编码。本文提出了一个几何特征网络,通过映射每个分割点云的点到一个特征图中,来生成一个密集的逐点特征。
(2)稠密颜色特征
图像特征生成网络是一个基于CNN的编码解码架构,将图像$(H, W, 3)$映射为$(H, W, d_{rgb})$,每个像素点的特征向量代表了输入图像中该点的外观信息。
像素级特征融合
关键思想是进行局部的主像素融合,而不是全局融合,这样我们可以基于每个融合后的特征进行预测。这样我们就可以选择物体的可见部分进行预测,从而减少了遮挡和语义分割的噪声的影响。
首先,利用相机固有参数投影到图像平面,将每个点的几何特征与图像特征关联起来。将配对的特征送入另一个网络,利用对陈下降函数来产生固定大小的全局特征,用来丰富每个像素级特征。
然后将每个像素特征输入到一个最终的网络来预测物体的6D位姿。这个网络用来从每个密集的融合特征预测一个姿态,最终获得P个姿态。
同时网络还输出每个预测姿态的置信度,用来评价那个姿态估计的结果最好。
损失函数
损失函数的设计与PoseCNN类似。
本文将损失函数定义为真实位姿的模型的采样点与预测位姿的模型的对应点之间的距离。
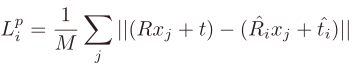
对于对称物体,损失函数定义为预测模型上每个点与真实位姿上最近的点之间的距离。

此外,由于每个像素的预测结果也同时输出了置信度,因此利用此置信度,对每个像素的损失进行加权。

迭代优化
以往的位姿估计算法,通常采用ICP来优化。但ICP的实时性不足够满足实际应用。
本文提出了一种基于神经网络的迭代优化方法,利用稠密融合的特征,可以改善最终的姿态估计结果,使其具有鲁棒性和快速性。
由于这个网络的作用是优化位姿估计的结果以减小误差,因此需要将上一个迭代的预测结果作为下一个迭代的输入的一部分。
该方法将先前的预测的姿态作为目标对象坐标系的估计,并将输入的点云转换为估计的坐标系中,通过这种方式转换的点云,就隐含了上一步估计的位姿。然后将转换后的点云输入到网络中,根据之前估计的位姿预测余项,通过不断迭代获得更精确的姿态估计。
问题
-
new_target和new_points是当前点云经过逆变换的点,这个点代表了什么
-
PoseNet输入的img是实例分割后的mask区域img,测试时实例分割部分如何实现
代码实现
参考:https://blog.csdn.net/weixin_44564705/article/details/125149491
下载代码
原作者:
1 | git clone https://github.com/j96w/DenseFusion |
1 | git clone -b Pytorch-1.0 https://github.com/j96w/DenseFusion |
RTX30系显卡适配:
环境搭建
(1)创建conda环境
使用anaconda创建一个虚拟环境
1 | conda create --name densefusion python=3.6 |
激活虚拟环境
1 | conda activate densefusion |
(2)配置CUDA和Pytorch
按照Github博主的Pytorch1.0分支,下载对应的版本。
1 | # 原版 |
cuda和pytorch安装后,可以命令行输入python,进入后使用以下代码确认cuda是否可用
1 | import torch |
(3)安装依赖
1 | pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple |
1 | conda install scipy pyyaml matplotlib -y |
数据集准备
参考:[[05_【数据集制作】制作自己的Linemod数据集(ObjectDatasetTools)]]
依赖库KNN
knn需要在自己的环境中进行编译,RTX30系显卡在这一步是会出现各种错误,推荐使用darpado修改的源码,并修改loss_refiner
1 | cd lib/knn |
执行后会在lib/knn路径下出现一个dist文件夹,里面是编译好的.egg文件,将此文件解压
1 | cd dist |
解压后会在dist文件夹里面生成两个文件夹,进入knn_pytorch文件夹里面,将下面两个文件移动到lib/knn里面:
1 | cd knn_pytorch |
开始训练
回到DenseFusion根目录,为sh文件添加可执行权限
1 | ./experiments/scripts/train_linemode.sh |
可能遇到的错误
- libgio-2.0.so.0: undefined symbol: g_uri_join while importing cv2 in conda environmnent
参考:https://github.com/opencv/opencv/issues/20212
1 | mv ~/anaconda3/envs/<anaconda_env>/lib/libgio-2.0.so.0 ~/anaconda3/envs/<anaconda_env>/lib/libgio-2.0.so.0.backup |
 微信支付
微信支付 支付宝
支付宝