制作自己的Linemod数据集(ObjectDatasetTools)
本文过程参考该项目: https://github.com/F2Wang/ObjectDatasetTools
本文修改和增加的代码已上传至Github: https://github.com/HaofeiMa/Linemod_Custom
(代码可能不太完善,为demo测试所写,仅供参考)
介绍
这个工具是一个纯python脚本,用来从RGBD相机中创建物体的掩码,边界框标签,3D物体mesh文件。
该工具可以为各种深度学习项目准备训练和测试数据,例如6D位姿估计、对象检测、实例分割等等。
准备工作
彩色打印arucomarkers文件夹下的aruco markers标记版,ID1-13,一共三页A4纸。
将标记一个一个剪下来,贴在物体周围。

使用conda新建一个虚拟环境
1 | conda create -n objectdatasettools python=2.7 |
安装依赖
1 | sudo apt-get install build-essential cmake git pkg-config libssl-dev libgl1-mesa-glx |
1 | pip install numpy Cython==0.19 pypng==0.0.18 scipy scikit-learn open3d==0.9.0 scikit-image tqdm pykdtree opencv-python==3.3.0.10 opencv-contrib-python==3.3.0.10 trimesh==2.38.24 |
如果出现
ImportError: No module named pip._internal.cli.main问题,则使用下面的指令安装pip。
python -m ensurepip
pip install --upgrade pip
如果出现
(from ipywidgets->open3d==0.9.0)相关的问题,使用conda install -c conda-forge ipywidgets安装ipywidgets,然后重新安装依赖open3d
1 | pip install pyrealsense2 |
录制视频
(1)如果有Realsense相机
使用Realsense相机录制一段物体的视频,对于旧模型使用record.py,对librealsense SDK 2.0使用recordf2.py。
1 | python record2.py LINEMOD/OBJECTNAME |
默认情况下,脚本在倒计时5后录制40秒,录制时间长度可以在record.py中的第20行进行修改。可以通过按“q”退出录制。
请稳定移动相机以获得物体的不同视图,同时始终保持 2-3 个标记在相机的视野范围内。
请注意,该项目假设所有序列都保存在名为“LINEMOD”的文件夹下,使用其他文件夹名称会导致错误发生。
如果使用record.py创建序列,彩色图像、深度图以及相机参数会自动保存在序列目录下。

(2)如果有现有的图像
如果已有彩色图像或者深度图像,则应将彩色图像(.jpg)放在名为“JPEGImages”的文件夹中,并将对其的深度图像放在“depth”文件夹中。
注意:该算法假定深度图与彩图对齐。将彩图按顺序从0.jpg、1.jpg、…、600.jpg和相应的深度图命名为:0.png,…,600.png,同时应在序列目录下创建一个名为“intrinsics.json”的文件,并按照如下形式手动输入相机参数
1 | {"fx": 614.4744262695312, "fy": 614.4745483398438, "height": 480, "width": 640, "ppy": 233.29214477539062, "ppx": 308.8282470703125, "ID": "620201000292"} |
获取帧之间的变换
计算第一帧的变换,以制定的间隔(可在config/registrationParameters修改间隔),将变换(4x4矩阵)保存为numpy数组。计算结果保存在LINEMOD/OBJECTNAME/transforms.npy
1 | python compute_gt_poses.py LINEMOD/OBJECTNAME |
或
1 | python compute_gt_poses.py all |
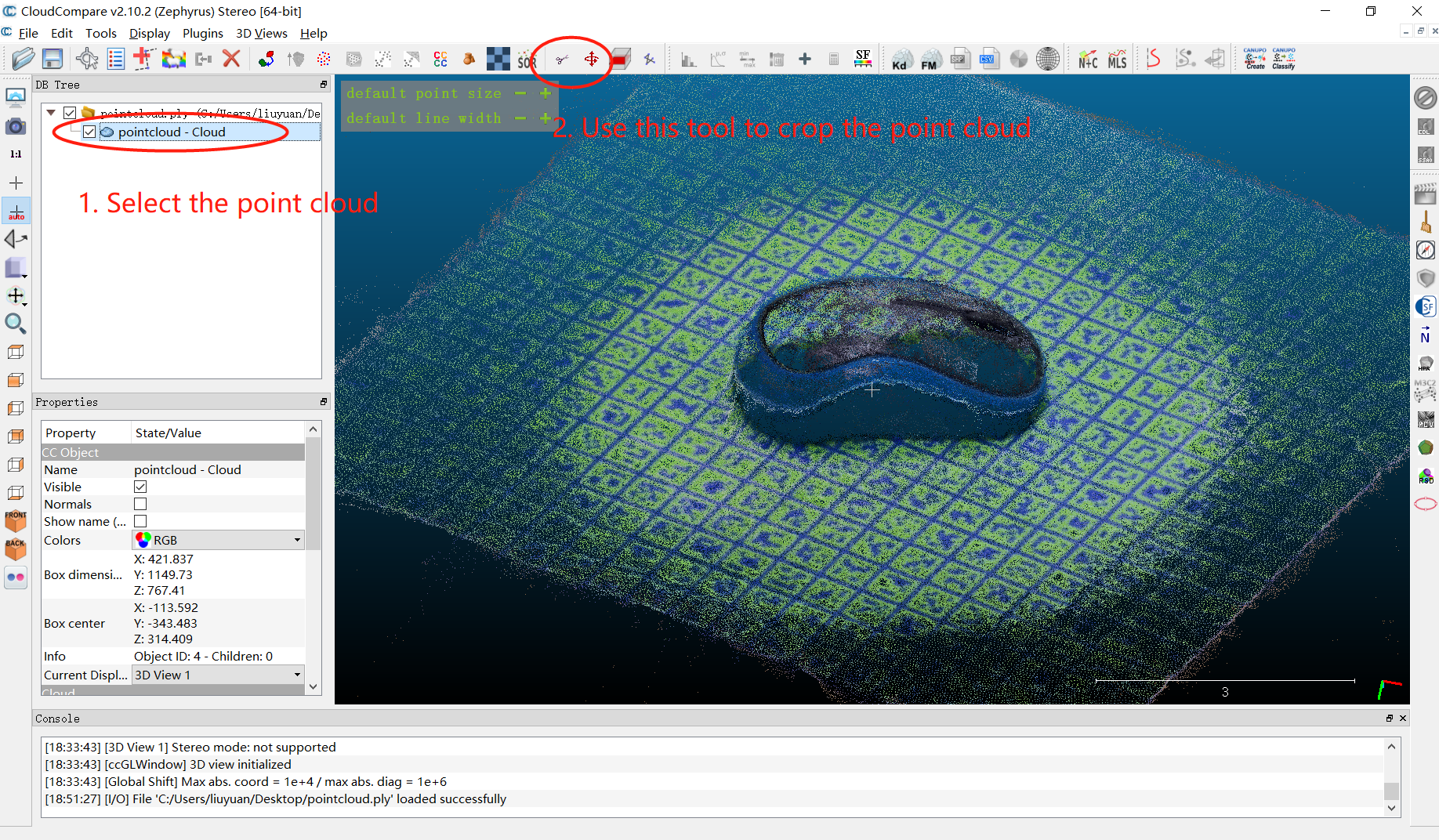
目标物体三维重建
1 | python register_scene.py LINEMOD/OBJECTNAME |
上面代码会原始的registeredScene.ply将保存在指定的目录下(例如,LINEMOD/OBJECTNAME/registeredScene.ply)。registerScene.ply是整个场景的点云,包括桌面、标记纸,物体等等相机中的对象。

1 | python register_segmented.py LINEMOD/OBJECTNAME |
使用上面的代码可跳过手动工作,来删除不需要的背景,并实现物体的三维重建
register_segmented.py会将物体点云转换为mesh网络。FILLBOTTOM设置为true,算法会自动使用平坦表面填充物体底部。
但是register_segmented.py可能会失败,这时候需要调整一些参数来使算法可以正常运行。最重要的参数是MAX_RADIUS,如果物体较大,需要增加此值以保证对象不会被截断。
调整MAX_RADIUS参数,使模型尽可能精准。生成后使用MeshLAB手动删除孤立的点和区域,然后手动保存一次。
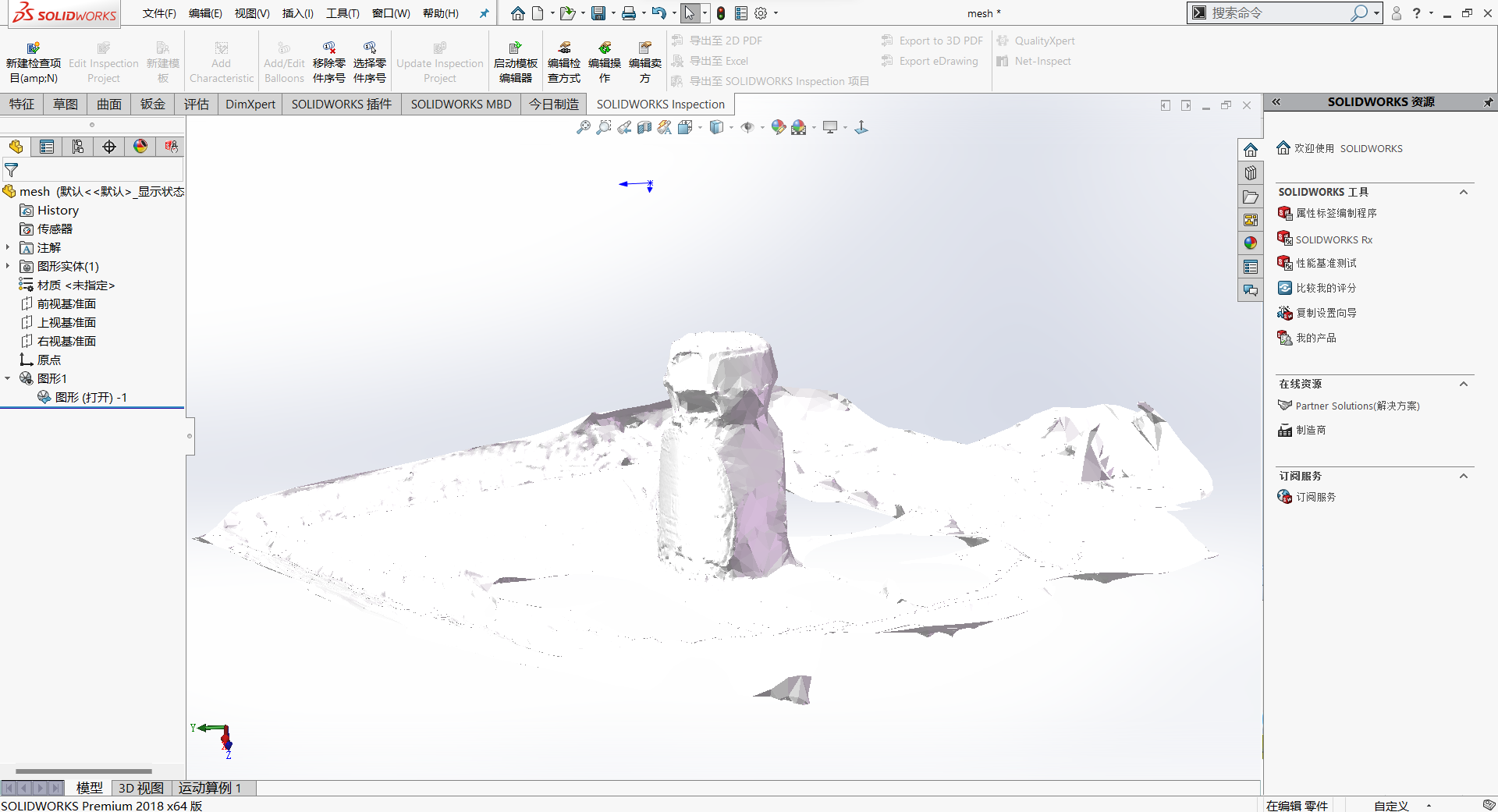
手动处理点云
如果上面的register_segmented.py处理结果比较满意,可以跳过该步骤。
将生成的点云数据registeredScene.ply使用meshlab打开:
- 删除背景
- 进行表面重建补全缺失的底部
- 处理重建后的网络
- 确保处理后的网格没有孤立地噪声
最终生成mesh网格文件。
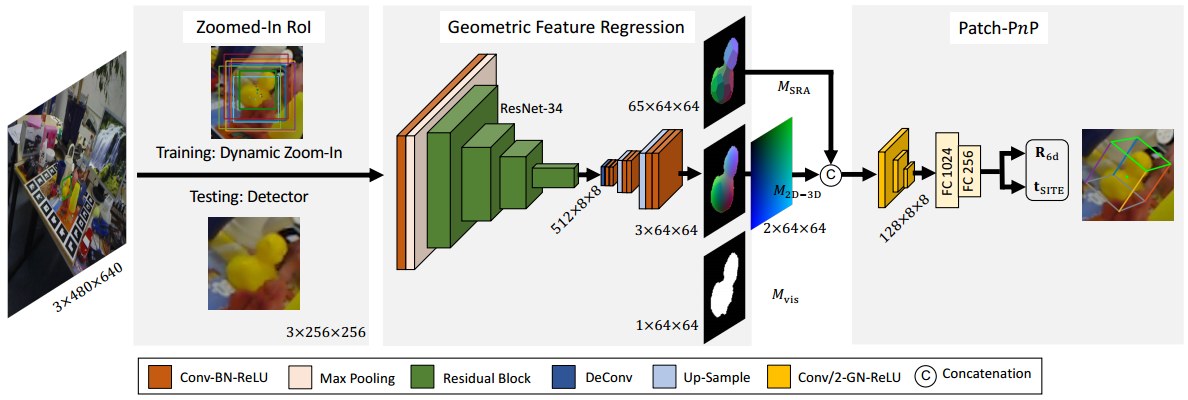
生成图像掩码和标签文件
当完成了物体mesh网格文件的生成后,使用以下程序创建图像掩码和标签
1 | python create_label_files.py all |
或
1 | python create_label_files.py LINEMOD/OBJECTNAME |
这一步骤会生成一个名为OBJECTNAME.ply的文件,用meshlab打开此文件,另存为mesh并取消勾选binary,保存的文件就是数据集的模型文件。其AABB以原点为圆心,并与OBB的尺寸相同,同时在mask文件夹下会生成图像的掩码,transforms文件夹下会保存新mesh的变换矩阵,labels文件夹内保存标签文件。
同时将打印出的min_xyz和size_xyz复制到models_info.yml文件中。
使用下面的命令可以检查创建的边界框和掩码的正确性:
1 | python inspectMasks.py LINEMOD/OBJECTNAME |
获得物体比例
1 | python getmeshscale.py |
将物体直径复制到models_info.yml文件中。
创建边界框标签
在获取了物体的mask后,使用下面的代码:
1 | python get_BBs.py |
会在根目录创建annotations.csv文件,包含所有图片的物体类别的标签和边界框信息。
匹配数据集格式
下面4个程序是自己写的,主要用来将生成的linemod数据集进行处理,整理成linemod_processed数据集的格式。
从annotations.csv中生成gt.yml与info.yml。需要修改每个物体对应的obj_id。
1 | python generate_yml.py LINEMOD/timer |
将图片重命名为如0000.png格式
1 | python rename.py all |
根据每个物体的图片数量划分数据集,生成train.txt与test.txt
1 | python data_divide.py all |
(将ply文件中的坐标单位由m转为mm),使用meshlab打开objectname.ply文件,删除无效点后保存为objectname_aligned.ply,勾选normal和color,取消勾选binary encoding。
然后运行下面的指令,将点云文件的单位由m转换为mm:
1 | python plym2mm.py all |
 微信支付
微信支付 支付宝
支付宝