【论文笔记】机器人动作、轨迹、过程模仿
1 AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
标题:AW-Opt:通过大规模模仿和强化学习机器人技能
作者团队:Google
期刊会议:CoRL
时间:2022
代码:https://awopt.github.io/
1.1 目标问题
强化学习可以实现目标任务,但是需要大量自主数据收集。模仿学习只能学习和演示一样程度的动作。
本文探索如何最好的结合两种方法,并进行扩展。实现大规模机器人学习。
1.2 方法
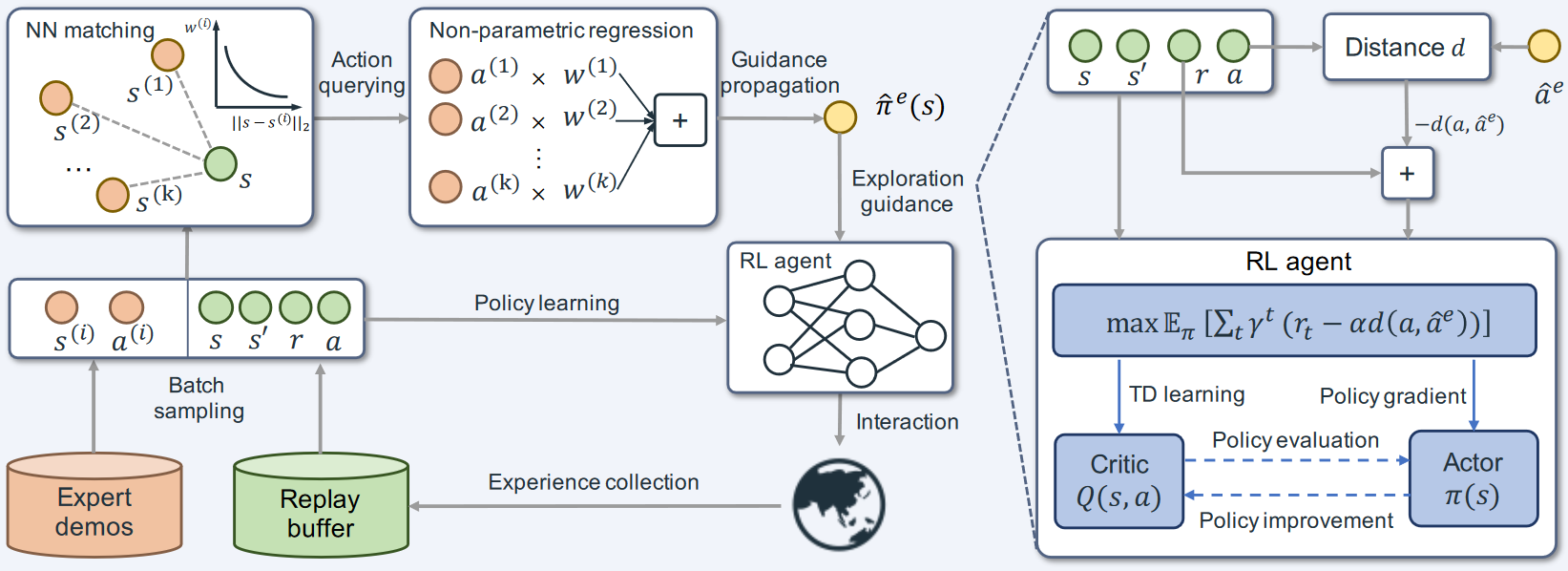
(1)任务场景与基础算法
本文以基于视觉的垃圾分类任务为例,机器人从不同对象类型(可回收物、不可回收对象)等垃圾箱中拾取特定类型的对象。
本文的算法为了研究IL+RL的扩展性,在QT-Opt和AWAC两种IL+RL算法的基础上进行研究。
(2)正样本过滤
两种基础算法性能不够好的原因可能有以下两点:
- 探索过程中增加了大量的失败事件、掩盖了最初的成功演示
- 算法在学习有效的Q函数,对actor进行更新之前,会删除预训练初始化。
为了解决这个问题,本文进行了以下两个修改:
- 为critic使用优先缓冲区,其中一半来自于成功事件奖励
- 对actor使用正向过滤,仅对通过过滤器的样本进行更新
(3)混合 actor-critic 探索
QT-Opt方法没有明确的actor,由于任务使用交叉熵利用critic来优化动作,因此可以视为隐式策略。
AWAC是一种actor-critic算法,通过对actor的动作采样来实现,而这种方式在训练初期,主要是critic进行学习,来确定哪些动作是好的。这种方式对于复杂的任务学习存在限制。
本文为了解决以上问题,结合两种算法,并比较了四种策略:仅actor探索、隐式critic策略、episode级随机切换策略(80%critic策略、20%actor)、step级随机切换策略、
2 DexMV: Imitation Learning for Dexterous Manipulation from Human Videos
标题:DexMV:模仿学习,从人类视频中进行灵巧操作
作者团队:University of California San Diego
期刊会议:ECCV
时间:2022
代码:https://github.com/yzqin/dexmv-sim
2.1 目标问题
由于多指机器人拥有高自由度关节、非线性驱动,因此需要大量的强化学习训练数据,而机器人数据收集困难,且仅使用仿真数据训练机器人运动也很不自然,能否利用人类与真实世界的交互经验来引导机器人?
2.2 方法
设计了一个基于模仿学习的平台
- 多指机器人复杂灵巧操作的模拟系统
- 记录人手执行相同任务的大规模演示(从视频中提取手部3D位置和物体姿态)
- 演示翻译方法:将人体动作转换为机器人演示
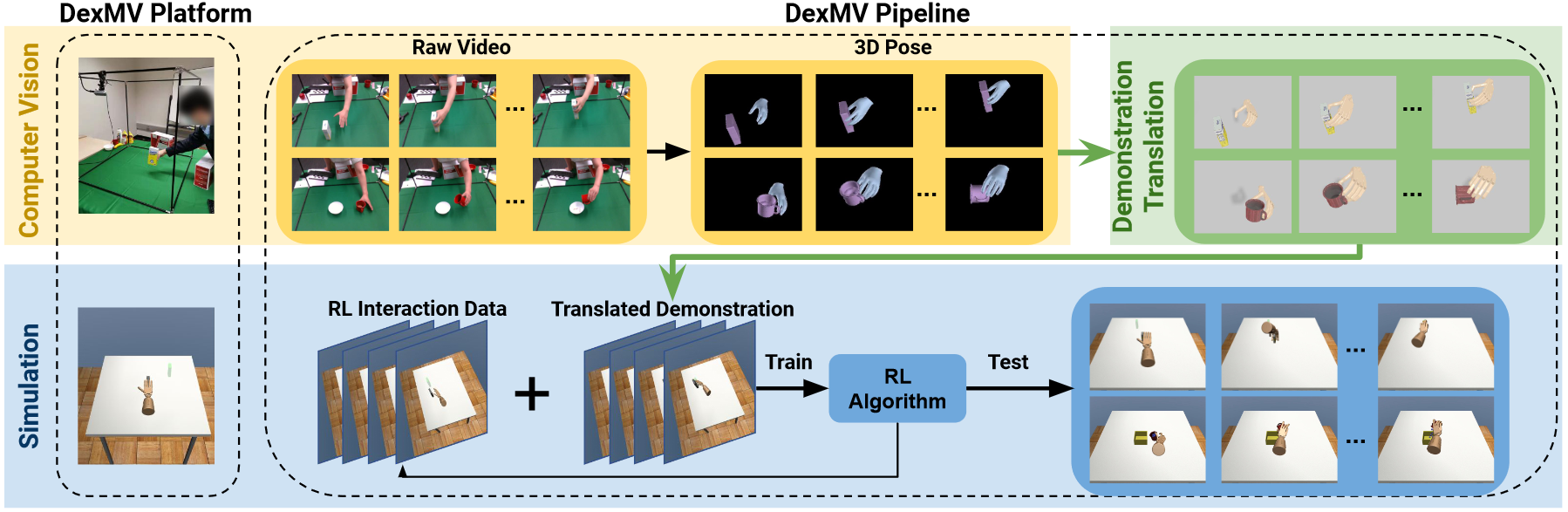
2.2.1 姿态估计
物体位姿估计:使用在YCB数据集上训练的PVN3D实现物体6D位姿的估计。
人手姿态估计:使用MANO模型表示人手关节,进行手部检测和实例分割,利用现有的模型估计手部关节。
2.2.2 演示数据转换
常见的模仿学习算法使用==机器人状态和动作==作为训练数据,而不是人手姿态。并且人手和灵巧手的运动学模型也不同。
(1)手部运动重定向
给定视频中估计的人手姿态序列,将其重定向为机器人关节角度序列。改过程可视为优化问题。
在大多数操作任务中,人类和机器人都是指尖接触物体,因此保留手掌根的指尖的空间向量。
但是这样可能会导致手指弯曲信息丢失,导致手指穿透物体,因此考虑同时优化手掌根到中指骨的向量。
(2)机器人动作估计
手部运动重定向提供了手部姿态到机器人关节角度的转换,但是关节扭矩是位置的,因此通过逆动力学函数,将关节角度拟合到连续的关节轨迹函数中,计算扭矩。在这个过程中,需要保证q’‘’(t)加加速度尽可能小。
(3)时间对齐
录制的视频帧率为30Hz,模拟运行的频率为120Hz,因此在训练之前,需要进行时间对齐,以模拟频率对机器人动作q(t)进行采样。
2.2.3 模仿学习
本文使用转换后的演示进行模仿学习,不使用行为克隆方法,而是使用模仿学习算法,并将演示合并到强化学习中。
本文考虑使用 $<S, A, P, R, \gamma>$ 的马尔科夫决策链,其中:
- $S$: 状态空间
- $A$: 动作空间
- $P(s_{t+1}|s_t, a_t)$: 是状态转移函数,在$t+1$步,给定动作$a_t$时,下一个状态$s_{t+1}$的概率密度
- $R(S, a)$: 奖励函数
- $\gamma$: 折扣因子
强化学习的目的是最大化策略$\pi(a|s)$下的预期奖励。给定演示轨迹${(s_i, a_i)}^n_{i=1}$,使用该轨迹和奖励,优化策略$\pi$。
本文使用生成对抗模仿学习GAIL,这是一种使用state-action动作密度匹配来学习策列的SOTA IL方法。通过最大限度的减小演示和动作的距离函数,实现动作模仿。
本文使用演示增强策略梯度进行强化学习。
2.3 总结
- 将真实世界人手姿态转换为机器人动作,加上物体位姿估计,作为演示数据用于后续模仿学习与强化学习。
- 使用生成对抗模仿学习GAIL
- 使用演示增强策略梯度进行强化学习
3 Learning and Retrieval from Prior Data for Skill-based Imitation Learning
标题:基于技能的模仿学习的先验数据的学习和检索
作者团队:The University of Texas at Austin
期刊会议:CoRL
时间:2022
代码:https://ut-austin-rpl.github.io/sailor
3.1 目标问题
模仿学习由于需要进行监督学习和较弱的泛化能力,因此可扩展性有限。
本文研究如何使用其他任务的先验数据,来稳定高效地学习新任务。
3.2 方法
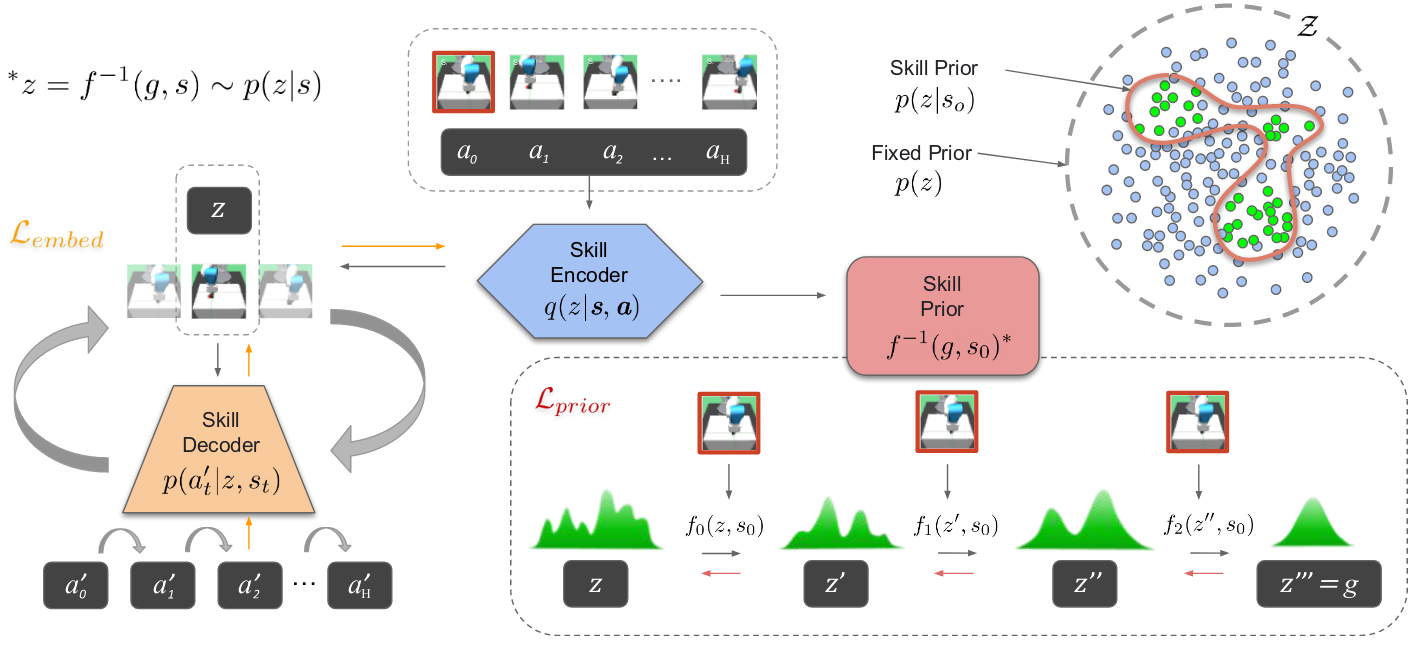
本文提出了一种基于技能的模仿学习框架,从先前的数据中提取运动技能,并随后调用这些学到的技能的目标函数策略。
(1)学习可预测的技能表示
通过使用变分自动编码器VAE编码小段轨迹来学习技能表示。为了提高技能的可预测性,将小段轨迹使用LSTM编码器编码为潜在技能的高斯分布,解码器也是一个LSTM网络。
对于每个时间步,将潜在特征z和给定的观察o,解码为动作a。
(2)基于检索的策略学习
为了提高任务策略的学习效果,从先前的数据集中检索与目标任务相关的数据。
策略学习阶段,使用LSTM策略通过观察历史的潜在技能,预测输出接下来要执行的技能z,这种方式可以利用丰富多样的先验交互知识,将其融入到策略中,从而在新环境中更有效的执行任务。
3.3 总结
使用变分自动编码器VAE处理子轨迹,形成一致的潜在技能表示。
使用LSTM编码解码技能表示,根据状态预测需要输出的技能。
4 VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors
标题:VIOLA:使用对象提议先验进行基于视觉的操作的模仿学习
作者团队:The University of Texas at Austin
期刊会议:CoRL
时间:2022
代码:https://ut-austin-rpl.github.io/VIOLA
4.1 目标问题
一种先进的模仿学习算法。
4.2 方法
本文实现了一种基于视觉的机器人操作任务模仿学习算法:
- 使用预训练的视觉模型生成通用的对象表示;
- 采用基于Transformer的策略,来推理这些表示,根据视觉预测动作;
(1)构建面向对象的表示
- 对象识别:使用预训练的RPN区域建议网络在工作空间图像上生成对象建议,并选择执行度最高的前K个建议。
- 对象特征表示:包含区域特征和上下文特征
- 区域特征:为每个建议区域设计视觉特征和位置特征,使用ROI Align从工作空间图像的ResNet18编码的特征途中提取特征;
- 上下文特征,包括全局特征、手眼相机图像特征和机器人状态的本体感知特征组成;
- 时间组合,将过去H+1步的特征和时间编码组合,构成面向对象的表示,来获得对象状态的时间依赖性和动态变化。
(2)基于Transformer的策略
使用多个Transformer编码器,处理一系列特征向量。
该策略网络将面向对象的区域特征和上下文特征作为输入token,并加入了一个动作token,通过动作监督学习,能够关注任务相关的区域。
最后利用两层全连接层和高斯混合模型输出动作。
4.3 总结
- 构建面向对象的特征(图像区域特征+机器人状态特征)
- 使用Transformer进行特征编码与预测
- 使用高斯混合模型输出动作。
5 SEIL: Simulation-augmented Equivariant Imitation Learning
标题:SEIL: Simulation-augmented Equivariant Imitation Learning
作者团队:Northeastern University
期刊会议:ICRA
时间:2022
代码:https://saulbatman.github.io/project/seil/
5.1 目标问题
机器人模仿学习中,样本获取非常困难,因为需要与现实世界进行交互。为了解决这个问题,本文在图像数据增强的基础上进行模仿学习。
5.2 方法
(1)数据增强
本文实现了一种专家数据增强方法Transition Simulation。通过将观察到的点云投影到模拟的机械臂姿态中,生成新的观察图像,从而模拟专家的state-action来增加数据多样性。
(2)等变行为克隆
利用机器人操作过程中的O(2)对称性(所有平面旋转和反射对称性),利用Steerable CNNs将策略自动泛化到不同的O(2)状态中。
5.3 总结
专家数据增强+等变行为克隆
6 Waypoint-Based Imitation Learning for Robotic Manipulation
标题:基于路标点的机器人操作模仿学习
作者团队:Stanford University
期刊会议:arXiv
时间:2023
代码:https://github.com/lucys0/awe
6.1 目标问题
模仿学习容易出现错误,特别是在执行复杂操作时。
使用路标点可以减少模仿学习中的错误,但是一般路标点需要认为监督,本文则是提出了一种自动生成路标点的方法。提高了模仿学习的成功率。
6.2 方法
本文设计了一种自动路标点提取方法,这是一个预处理模块,因此很容易添加到其它行为克隆算法中。本文举例了两种先进的模仿学习算法:扩散策略和基于Transformer的动作。
(1)重建损失
定义了一种损失:给定路标点后重建轨迹的质量,通过最小化原始轨迹与根据路标点重建的轨迹之间的偏差,来使得路标点能尽可能代替真实轨迹。
(2)路径点选择动态规划
使用一种简单而动态规划算法,用于选择最小数量的路径点,并保证重建的误差满足要求。
6.3 总结
一种自动路标点提取算法,用于对行为克隆数据进行预处理。
7 Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
标题:Mobile ALOHA:通过低成本全身远程操作学习双手移动操作
作者团队:Stanford University
期刊会议:无
时间:2024
代码:https://mobile-aloha.github.io/
7.1 目标问题
目前的大多数从人类演示中模仿学习的机器人技术集中在桌面操作,缺乏一般有用的任务所需的机动性和灵活性,本文主要是开发了一个移动机器人,实现移动+双手的模仿学习。
7.2 论文中提到的学习方法
(0)基础模仿学习算法
- ACT: Learning fine-grained bimanual manipulation with low-cost hardware
- 扩散策略: Diffusion policy: Visuomotor policy learning via action diffusion
- VINN: The surprising effectiveness of representation learning for visual imitation
(1)BC 的改进
行为克隆 BC 与各种架构相结合
- Rt-1: Robotics transformer for real-world control at scale
- Bc-z: Zero-shot task generalization with robotic imitation learning
- What matters in learning from offline human demonstrations for robot manipulation
- Behavior transformers: Cloning k modes with one stone
使用新的训练目标
- Roboagent: Towards sample efficient robot manipulation with semantic augmentations and action chunking
- Diffusion policy: Visuomotor policy learning via action diffusion
- Implicit behavioral cloning
- The surprising effectiveness of representation learning for visual imitation
- Learning fine-grained bimanual manipulation with low-cost hardware
正则化
- Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration
Motor Primitives
- Hierarchical neural dynamic policies
- Dynamical movement primitives: learning attractor models for motor behaviors
- Learning motor primitives for robotics
- Using probabilistic movement primitives in robotics
- Learning and generalization of motor skills by learning from demonstration
- Learning periodic tasks from human demonstrations
数据预处理
- Waypoint-based imitation learning for robotic manipulation
(2)多任务或少镜头模仿学习
- Transformers for one-shot visual imitation
- One-shot imitation learning
- Learning manipulation skills from a single demonstration
- One-shot visual imitation learning via meta-learning
- Task-embedded control networks for few-shot imitation learning
- Coarse-to-fine imitation learning: Robot manipulation from a single demonstration
- Demonstrate once, imitate immediately (dome): Learning visual servoing for one-shot imitation learning
- One-shot imitation from observing humans via domain-adaptive metalearning
(3)语言条件的模仿学习
- Rt-1: Robotics transformer for real-world control at scale
- Bc-z: Zero-shot task generalization with robotic imitation learning
- Cliport: What and where pathways for robotic manipulation
- Perceiver-actor: A multi-task transformer for robotic manipulation
(4)从演示数据模仿
- From play to policy: Conditional behavior generation from uncurated robot data
- Learning latent plans from play
- Latent plans for task-agnostic offline reinforcement learning
- Mimicplay: Longhorizon imitation learning by watching human play
(5)使用人类视频模仿
- Learning generalizable robotic reward functions from" in-the-wild" human videos
- Model-based inverse reinforcement learning from visual demonstrations
- Perceptual values from observation
- R3m: A universal visual representation for robot manipulation
- Real-world robot learning with masked visual pre-training
- Concept2robot: Learning manipulation concepts from instructions and human demonstrations
- Avid: Learning multi-stage tasks via pixel-level translation of human videos
- Learning by watching: Physical imitation of manipulation skills from human videos
(6)针对特定任务的模仿学习
- Coarse-to-fine imitation learning: Robot manipulation from a single demonstration
- Perceiver-actor: A multi-task transformer for robotic manipulation
- Transporter networks: Rearranging the visual world for robotic manipulation
(7)针对模仿学习的通用化用于新的场景或对象
- Rt-1: Robotics transformer for real-world control at scale
- Rt-2: Vision-language-action models transfer web knowledge to robotic control
- Bridge data: Boosting generalization of robotic skills with cross-domain datasets
- Bc-z: Zero-shot task generalization with robotic imitation learning
- Robot peels banana with goalconditioned dual-action deep imitation learning
(8)从不同但类似的机器人上收集数据模仿
- Robocat: A self-improving foundation agent for robotic manipulation
- Open X-Embodiment: Robotic learning datasets and RT-X models
- In Towards Generalist Robots: Learning Paradigms for Scalable Skill Acquisition
- Octo: An open-source generalist robot policy
7.3 总结
 微信支付
微信支付 支付宝
支付宝