HDF5数据文件格式
[!abstract]
HDF5数据文件格式的简单介绍与基本使用方法。
1 HDF5 格式简介
1.1 什么是 hdf5 文件
HDF5是一种常见的跨平台数据储存文件,可以存储不同类型的图像和数据,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。
可以把HDF5文件想象成一个容器,这个容器由多个不同类型的数据对象组成。数据对象可以是任意类型,例如:图片、表格、图像,甚至文档(PDF、Excel)。
1.2 hdf5 文件结构
HDF5 文件一般以 .h5 或 .hdf5 作为后缀名,其文件结构包括两部分:Groups 和 Datasets。
- Group: 类似于文件夹,负责管理数据对象
- Datasets: 类似于 numpy 中的数组 array,一个数据集由元数据(metadata)和数据本身(data)组成
- Metadata: 元数据
- Datatype: 数据类型
- Dataspace: 原始数据的秩和维度
- Properties: 该数据集的分块存储以及压缩情况
- Chunked:
- Chunked & Compressed:
- Attributes: 为该数据的其它自定义属性
- Data Values:
- Metadata: 元数据
(1)Group 组
组负责管理数据对象。每个HDF5文件含有一个根组,根组包含其他组或者链接到其他文件的对象。组和组的成员与文件和文件夹类似,HDF5中对象也可以使用路径来表示:
/代表根组/a代表根组下的a成员/a/b代表组a下的一个成员,a是根组/下的成员
(2)Datasets 数据集
一个数据集由元数据(metadata)和数据本身(data)组成。
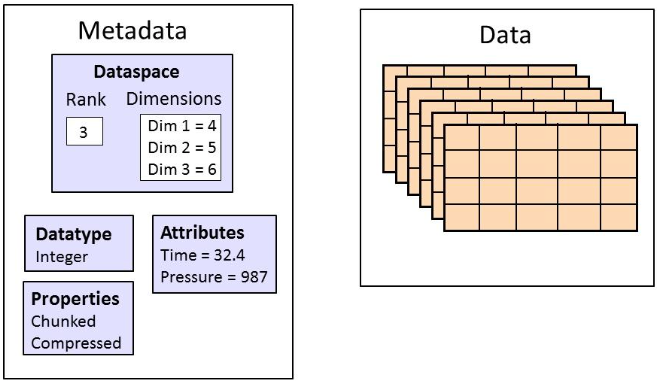
其中的 Metadata 包括一下几个部分:数据类型(datatype)、数据空间(dataspace)、性质(property)、属性(attribute)。
(3)Datatype 数据类型
数据类型描述数据集中元素的数据类型,例如 float。
- 内置数据类型:包括标准数据类型和原生数据类型
- 衍生数据类型:例如符合数据类型(16位整型、1个字符、一个2x3x2的浮点数组组合而成)
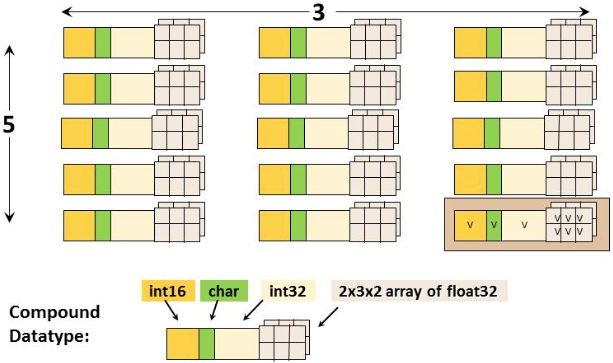
(4)Dataspace数据空间
描述数据集内部数据元素(data element)的分布情况:
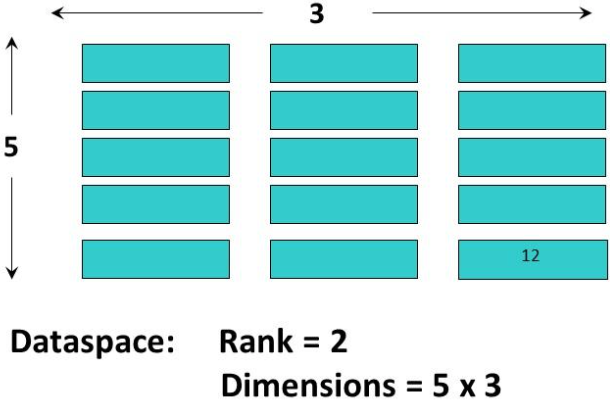
- Rank:表示数据集维度的个数(例如下图中数据维度个数为2,即2维数组)
- Dimensions:数据空间的维度(数据空间的维度为5x3)
- NULL:代表数据集内没有任何数据元素
- 标量:代表只有一个元素
- 向量:代表数据集是一个数组
数据空间的维度可以是固定的,也可以是不固定的。如果是不固定的,代表该数据集的大小是可变的(例如,可扩展的数据集)。
(5)Properties 性质
HDF5包含很多默认的性质,可以是用HDF5 Property List API来修改这些性质。
(6)Attribute 属性
属性包含一个名称(name)和一个值(value),是对HDF5对象的一些额外描述。通常都是一些很小的、用户自定义的元数据。
二、Python 操作HDF5文件
(1)使用 h5py 包
1 | import h5py |
(2)创建 hdf5 文件:
1 | # 创建 hdf5文件 |
最后得到的 hdf5 文件结构如下:
1 | +-- '/' |
(3)读取 hdf5 文件
1 | # 读取 hdf5 文件 |
参考:
 微信支付
微信支付 支付宝
支付宝