Mat img = imread("E:/Program/OpenCV/vcworkspaces/knn_test/images/data/digits.png"); Mat gray; cvtColor(img, gray, COLOR_BGR2GRAY); int b = 20; int m = gray.rows / b; //原图为1000*2000 int n = gray.cols / b; //裁剪为5000个20*20的小图块 Mat data, labels; //特征矩阵
for (int i = 0; i < n; i++) { int offsetCol = i * b; //列上的偏移量 for (int j = 0; j < m; j++) { int offsetRow = j * b; //行上的偏移量 //截取20*20的小块 Mat tmp; gray(Range(offsetRow, offsetRow + b), Range(offsetCol, offsetCol + b)).copyTo(tmp); //reshape 0:通道不变 其他数字,表示要设置的通道数 //reshape 表示矩阵行数,如果设置为0,则表示保持原有行数不变,如果设置为其他数字,表示要设置的行数 data.push_back(tmp.reshape(0, 1)); //序列化后放入特征矩阵 labels.push_back((int)j / 5); //对应的标注 } }
data.convertTo(data, CV_32F); //uchar型转换为cv_32f int samplesNum = data.rows; int trainNum = 500; Mat trainData, trainLabels; trainData = data(Range(0, trainNum), Range::all()); //前3000个样本为训练数据 trainLabels = labels(Range(0, trainNum), Range::all());
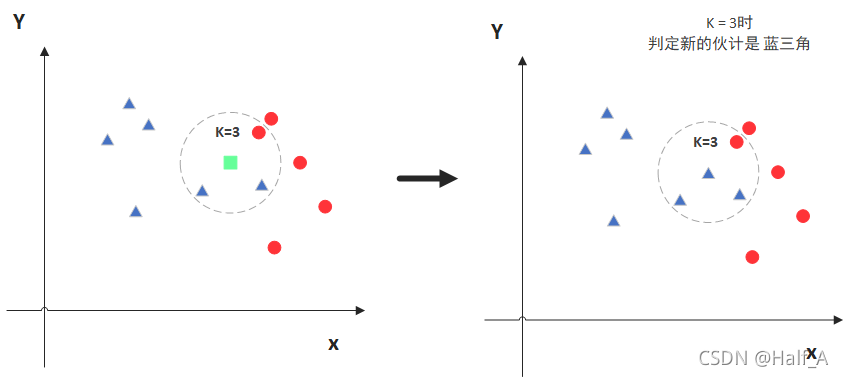
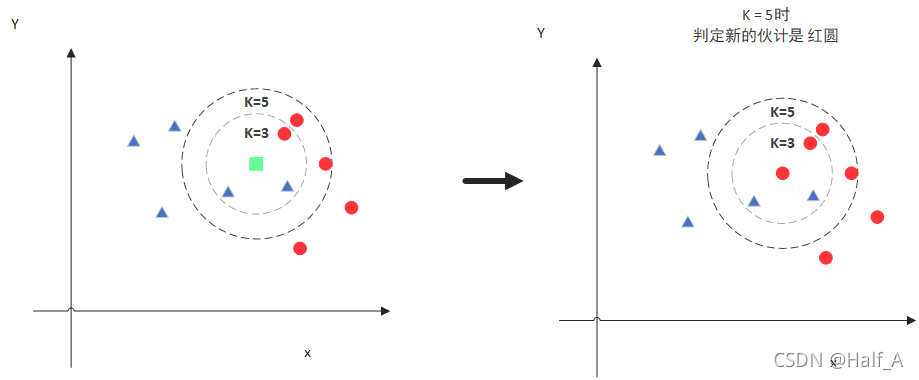
//使用KNN算法 int K = 5; Ptr<TrainData> tData = TrainData::create(trainData, ROW_SAMPLE, trainLabels); model = KNearest::create(); model->setDefaultK(K); model->setIsClassifier(true); model->train(tData); //预测分类 double train_hr = 0, test_hr = 0; Mat response; // compute prediction error on train and test data for (int i = 0; i < samplesNum; i++) { Mat sample = data.row(i); float r = model->predict(sample); //对所有行进行预测 //预测结果与原结果相比,相等为1,不等为0 r = std::abs(r - labels.at<int>(i)) <= FLT_EPSILON ? 1.f : 0.f;
if (i < trainNum) train_hr += r; //累积正确数 else test_hr += r; }

 微信支付
微信支付 支付宝
支付宝