【深度学习笔记02】数据操作的实现与线性代数基础
一、数据操作与数据预处理
1.1 数据操作
(1)N维数组
0维,标量,表示一个类别
1 | 1.0 |
1维,向量,表示一个特征向量
1 | [1.0, 2.7, 3.4] |
2维,矩阵,表示一个样本或特征矩阵
1 | [[1.0, 2.7, 3.4] |
3维,表示一个RGB图片(宽×高×通道)
1 | [[[1.0, 2.7, 3.4] |
4维,表示一个视频或RGB图片的批量(批量大小×宽×高×通道)
1 | [[[[... |
5维,表示一个视频批量(批量大小×时间×宽×高×通道)
1 | [[[[[... |
(2)数组相关
创建数组需要
- 形状
- 每个元素的数据类型
- 每个元素的值
访问元素
- 一个元素:[1, 2]
- 一行:[1, :]
- 一列:[:, 1]
- 子域:[1:3, 1:]
- 跳跃访问:[::3, ::2]
1.2 数据操作的实现
(1)导入torch
1 | import torch |
(2)创建张量
1 | x = torch.arange(10) |
(3)获取张量的形状
1 | x.shape |
(4)获取张量中元素的个数
1 | x.numel() |
(5)改变张量的形状
1 | X = x.reshape(3, 4) |
注意:reshape只是创建了一个浅拷贝,例如
a = torch.arange(6)
b = a.reshape((2,3))
b[:]=2
结果运算过后,a也变成了tensor([2, 2, 2, 2, 2, 2])
相当于b创建了一个a的view,只是用特定的方式观察a,地址空间仍然是同一个。
(6)创建初始化矩阵
1 | torch.zeros((2, 3, 4)) |
(7) 将列表转换为张量
1 | torch.tensor(list) |
(8)张量的标准运算符是按元素运算
1 | x = torch.tensor([1.0, 2, 4, 8]) |
(9)多个张量连在一起
1 | X = torch.arange(12).reshape((3, 4)) |
(10)张量元素求和
1 | X.sum() |
(11)广播机制:形状不同的张量可以通过广播实现按元素运算
1 | a = torch.arange(3).reshape((3, 1)) |
(12)转换为numpy张量
1 | A = X.numpy() # numpy.ndarray |
1.3 数据预处理实现
(1)创建数据集
创建一个人工数据集,并存储在csv逗号分隔值文件
1 | import os |
(2)从创建的csv文件中加载原始数据集
1 | # 如果没有安装pandas,只需取消对以下行的注释来安装pandas |
(3)处理缺失数据
常见的方法包括:
- 将缺失数据的行删除
- 插值
对于数值数据,进行插值替换
1 | inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 1] |
对于类别值或离散值,我们将NaN视为一个类别,再转换成数值类型
1 | inputs = pd.get_dummies(inputs, dummy_na=True) |
(4)数据转换张量
由于读取的数据条目都是数值类型,可以转换为张量格式。
1 | import torch |
二、线性代数的实现
2.1 线性代数
(1)标量
标量,由只有一个元素的张量表示
1 | import torch |
(2)向量
向量是由标量组成的列表
1 | x = torch.arange(4) |
(3)矩阵
通过二维数组作为矩阵
1 | A = torch.arange(20).reshape(5, 4) |
矩阵的转职
1 | A.T |
(4)张量的形状
访问向量的长度
1 | len(x) |
访问张量的形状
1 | x.shape |
(5)张量的运算
给定具有相同形状的任何两个张量,任何按元素二元运算的结果都是相同形状的张量
1 | A = torch.arange(20, dtype=torch.float32).reshape(5, 4) |
计算元素的和
1 | x.sum() #直接使用得到的是一个标量,不管矩阵是什么维度都得到标量 |
对于一个张量,其有三个维度,可以理解为RGB图像的(宽,高,通道数),或者直观理解为一个长方体的(宽,长,高)
其高度方向或者RGB的通道数是最高维度,也就是第0轴。
对于axis=0进行求和,相当于将长方体高度方向压扁,或者将RGB三个通道合成一个通道
对于axis=1进行求和,相当于将长方体长度方向压扁,或者将RGB图像沿每个通道的高方向压扁
对于axis=2进行求和,相当于将长方体宽度方向压扁,或者将RGB图像沿每个通道的宽方向压扁
此外sum方法还有一个keepdims参数,如果为True,那么将在求和时保持维度不变,将被压扁的维度设置为1。(这样方便通过广播实现A/A.sum)
计算平均值
1 | A.mean |
(6)矩阵的乘法
按元素乘
1 | A * B |
点积是按元素乘积的和
1 | y = torch.ones(4, dtype = torch.float32) |
矩阵乘向量
1 | torch.mv(A, x) |
矩阵乘矩阵
1 | torch.mm(A, B) |
(7)范数
L2范数是向量元素平方和的平方根
1 | torch.norm(u) |
L1范数是向量元素的绝对值之和
1 | torch.abs(u).sum() |
矩阵的F范数是矩阵元素的平方和的平方根
1 | torch.norm(torch.ones(A)) |
三、矩阵计算
3.1 梯度
梯度是导数从标量拓展到向量的形式
(1)标量对向量的导数
$x = [x_1, x_2, \cdots, x_n].T$
$\frac{\partial y}{\partial \textbf{x}}=[\frac{\partial y}{\partial x_1},\frac{\partial y}{\partial x_2},\cdots,\frac{\partial y}{\partial x_n}]$
例如,对于函数$y=x_1^2+2x_2^2$,其对向量$\textbf x=[x_1, x_2]$的导数是
$\frac{\partial y}{\partial \textbf x} = \frac{\partial x_1^+2x_2^2}{\partial \textbf x}=[2x_1, 4x_2]$
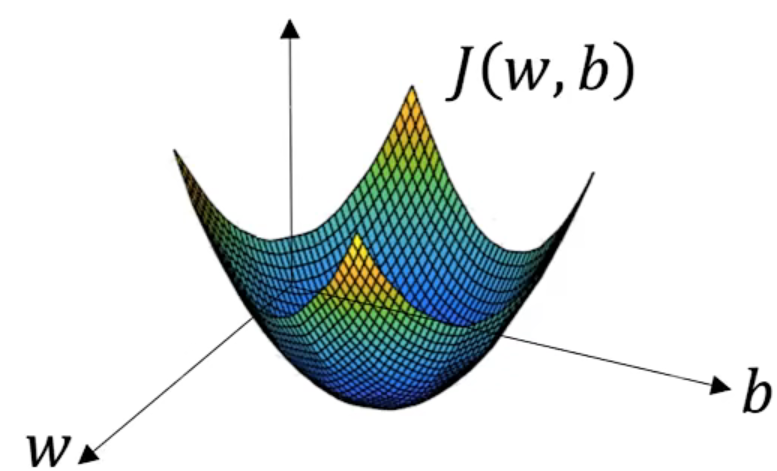
可以直观理解为$y=x_1^2+2x_2^2$是一圈圈椭圆,对于任意给定的$[x_1, x_2]$,都可以找到$[2x_1, 4x_2]$这个方向是$y$下降最快的方向。即梯度就是函数值下降最快的方向。
(2)向量对标量的导数
$y = [y_1, y_2, \cdots, y_n].T$
$\frac{\partial \textbf y}{\partial x}=[\frac{\partial y_1}{\partial x},\frac{\partial y_2}{\partial x},\cdots,\frac{\partial y_n}{\partial x}].T$
即$\frac{\partial y}{\partial \textbf{x}}$是行向量,$\frac{\partial \textbf y}{\partial x}$是列向量。
(3)向量对向量的导数
向量对向量的导数是一个矩阵:
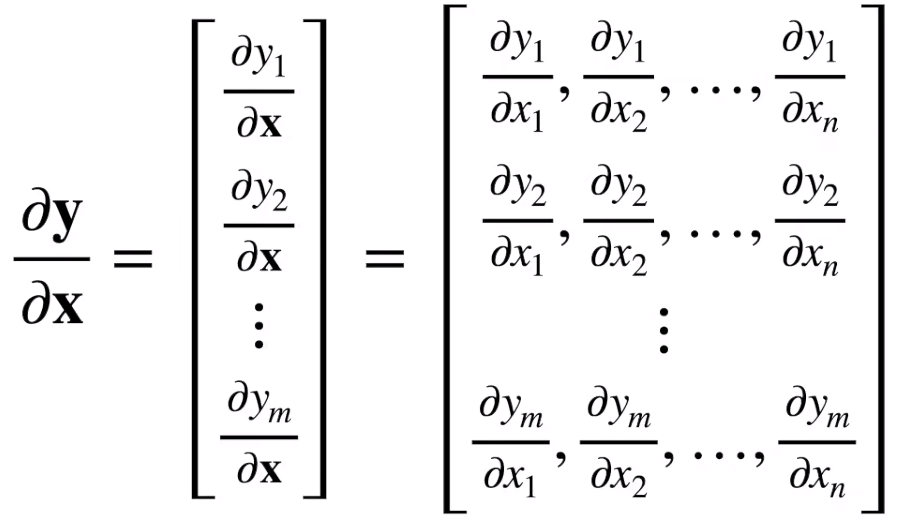
3.2 向量链式法则
标量的链式法则:
$y=f(u),u=g(x)$,则$\frac{\partial y}{\partial x}=\frac{\partial y}{\partial u}\frac{\partial u}{\partial x}$
向量的链式法则:
$\frac{\partial y}{\partial \textbf x}=\frac{\partial y}{\partial u}\frac{\partial u}{\partial \textbf x}$ (1,n) = (1, )(1, n)
$\frac{\partial y}{\partial \textbf x}=\frac{\partial y}{\partial \textbf u}\frac{\partial \textbf u}{\partial \textbf x}$ (1,n) = (1, k)(k, n)
$\frac{\partial \textbf y}{\partial \textbf x}=\frac{\partial \textbf y}{\partial \textbf u}\frac{\partial \textbf u}{\partial \textbf x}$ (m,n) = (m,k)(k.n)
3.3 自动求导
自动求导是计算一个函数在指定值上的导数。
(1)计算图
计算图是将代码反结成操作子,将计算表示成一个无环图。相当于将函数求导过程使用链式法则求导
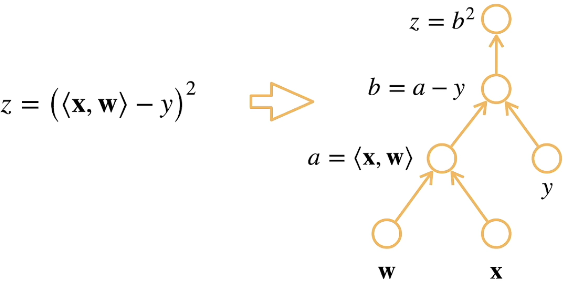
(2)自动求导的模式
链式法则:$\frac{\partial y}{\partial x}=\frac{\partial y}{\partial u_n}\frac{\partial u_n}{\partial u_{n-1}}\cdots \frac{\partial u_2}{\partial u_1}\frac{\partial u_1}{\partial x}$
-
正向积累:$\frac{\partial y}{\partial x}=\frac{\partial y}{\partial u_n}(\frac{\partial u_n}{\partial u_{n-1}}(\cdots (\frac{\partial u_2}{\partial u_1}\frac{\partial u_1}{\partial x})))$
-
反向传递:$\frac{\partial y}{\partial x}=(((\frac{\partial y}{\partial u_n}\frac{\partial u_n}{\partial u_{n-1}})\cdots) \frac{\partial u_2}{\partial u_1})\frac{\partial u_1}{\partial x}$
一般对于输入数据会先正向计算结果,再反向计算梯度,正向计算时会保存所有的中间变量。计算梯度的时候已经有了abz的具体值了,直接带入就能得到导数,比如dz/db=2b。同理其它操作子的导数也可以直接带数得到,根据链式法则最终的梯度就是各个操作子导数的乘积。
(3)自动求导的pytorch实现
假设对函数$\textbf y=2\textbf x^T \textbf x$对于列向量$\textbf x$求导
1 | import torch |
有时我们需要将某些参数移动到计算图之外:
1 | # 清空x.grad |
上面的步骤就实现了将y这个参数的当前值保存出来记为u,而y不受影响,在深度学习中会用到这种操作。
 微信支付
微信支付 支付宝
支付宝