【论文笔记】Reskill基于技能的适应性动作空间学习
一、论文笔记
标题:剩余技能策略:学习基于技能的适应性行动空间,用于机器人强化学习
作者团队:昆士兰科技大学
期刊会议:CoRL
时间:2022
代码:https://krishanrana.github.io/reskill
1.1 目标问题
基于技能的学习已经成为加速机器人学习的方法,技能从专家演示中提取,是短序列的单步操作(平移、抓取、抬起等动作),这些技能嵌入到潜在空间中,构成上层 RL 策略的行动空间。但是这种方式存在一些问题:
- 对所有技能进行随机抽样探索,效率极低,因为其中只有一小部分技能与当前执行的任务相关,并且这些相关的技能通常不会聚集在技能空间的同一邻域内。
- 该方法假设技能是最优的,并且下层的任务来自于技能空间的相同分布,因此学习的通用性和变化适应性有限,例如从移动方块中学习技能,则无法应对障碍物、物体变化、不同摩擦等情况。
为解决上述问题,本文提出了以下创新方法,称为残差技能策略(Residual Skill Policies,ReSkill):
- 状态条件技能先验:对相关技能进行采样来引导探索
- 底层残差策略:通过对技能进行细粒度的技能适应,实现任务变化的适应
1.2 方法
总的来说,该方法将经典控制器产生的演示轨迹分解为与任务无关的技能,并将其嵌入到连续到技能空间中,利用技能空间实现真正的通用学习,上层智能体能够从技能空间中访问但不动作,降低了对数据集详细程度的要求。
- 从现有控制器中提取技能
- 学习技能嵌入和先验技能
- 训练一个分层强化学习策略,在技能空间中使用底层残差适应性策略。
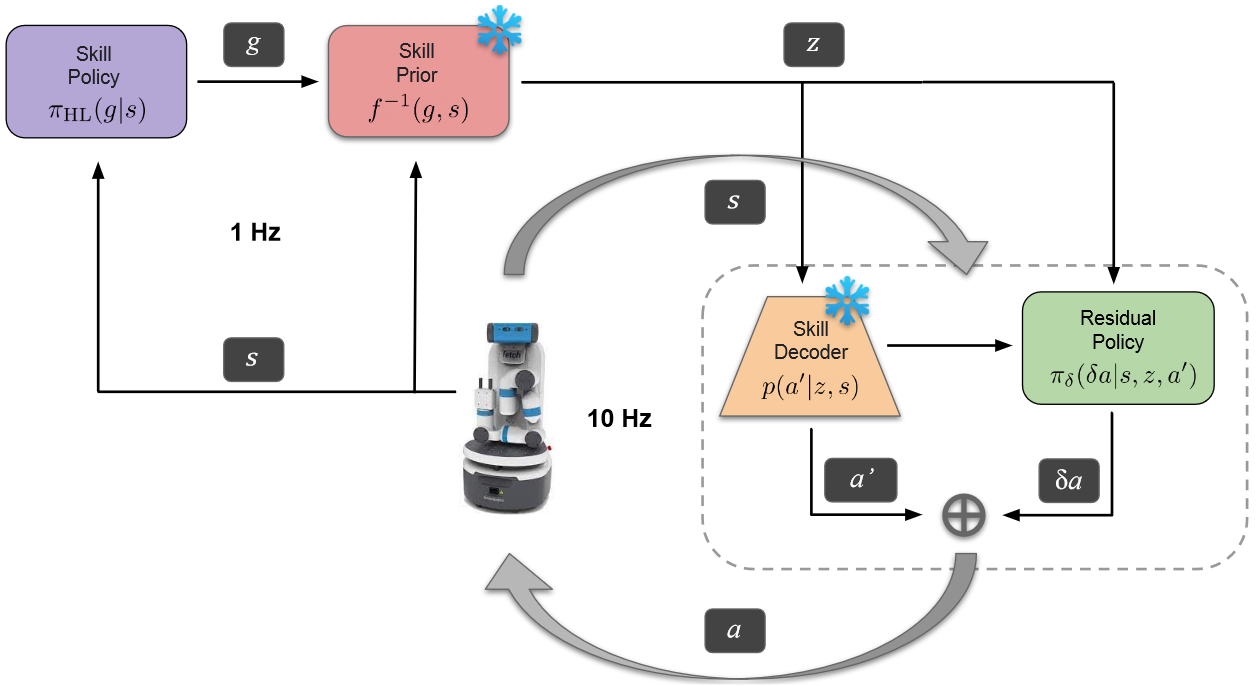
(1)数据收集
本文通过手动控制收集演示数据(基本操作任务,如推物体、抓物体),虽然任务简单,但轨迹包含复杂的技能,可以重新组合解决复杂的任务。
轨迹是由 state-action 成对组成的,本文从中随机切片 $H$ 长度的片段进行无监督技能提取,利用提取的动作 a 和状态 s 学习下一小节中的 state-action。
其中状态 s 包括关节角度、关节速度、夹具位置、物体位置,动作是连续的 4D 向量,包括末端位置和速度。
(2)学习强化学习的状态条件技能空间
- 将提取的技能嵌入到潜在空间中:使用变分自动编码器 VAE 将技能 $a$ 嵌入到潜在空间中,VAE 包括编码器和解码器,编码器将完整的 state-action 序列编码为 $z$,解码器根据当前状态 $s_t$ 和技能编码 $z$ 重建动作。
- 在探索过程中采样的技能状态条件先验:学习潜在技能空间上的条件概率密度。传统的高斯密度不能处理多模态信息,本文使用 real NVP 方法,实值非体积保留变换。学习从 $Z\times S->G$ 的映射,该映射就可以从简单分布 G 变换到技能空间 Z,因此 f 就是技能先验。
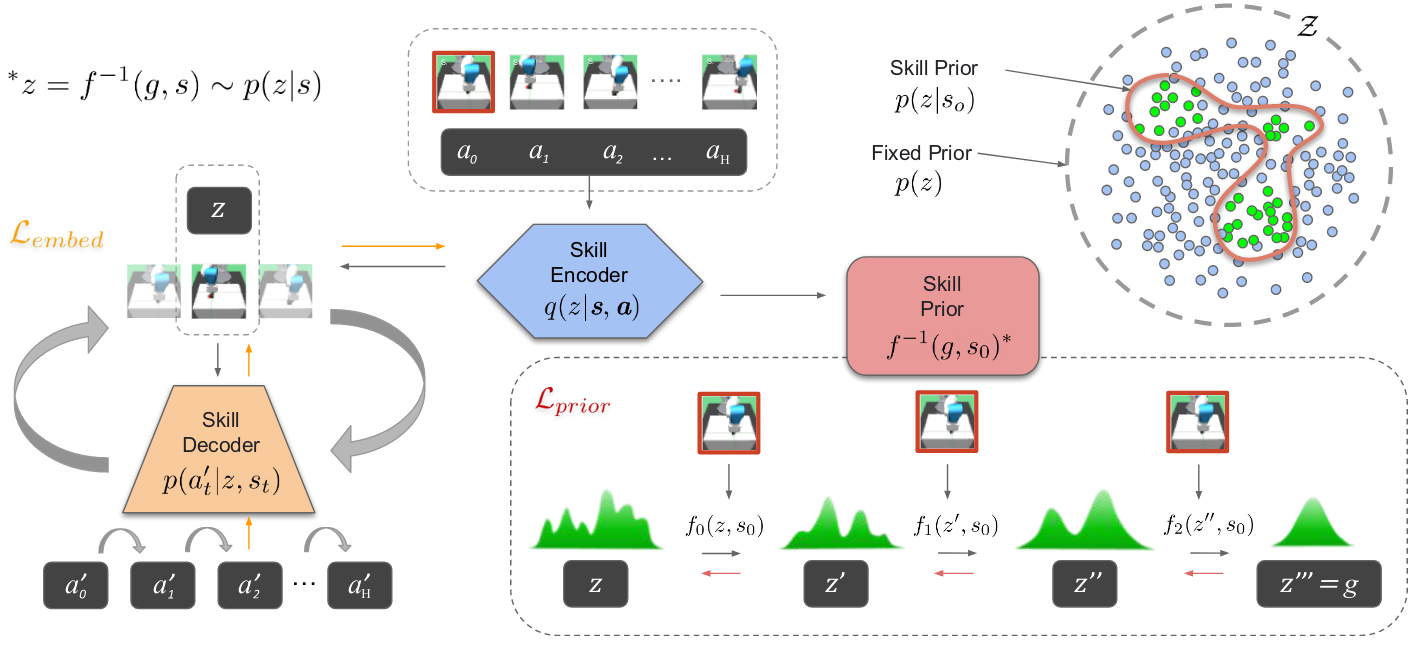
变分自编码器,是一种深度生成模型
传统:传统的自编码器包括编码器和解码器两部分,经过反复训练,输入数据被编码成一个编码向量,编码向量的每一个维度表示学习到的数据的特征,解码器尝试从编码向量中解码原始输入
缺陷:传统的方法,使用单个值表示输入在某个潜在特征的表现。但实际上,将潜在特征表示为可能的取值范围会更合理。
改进:因此变分自编码器就是使用取值的概率分布,代替原来的单值表示特征。
优势:每个潜在特征表示为概率分布,解码时从潜在状态分布中随机采样,生成一个编码向量作为解码器的输入。实现了连续且平滑的潜在空间表示(潜在空间中彼此相邻的值重构出的结果相似)
参考理解:https://zhuanlan.zhihu.com/p/64485020
(3)状态条件技能空间中的强化学习
一旦训练完成,解码器和技能先验权重就会被冻结,并合并到 RL 框架中。高级强化学习策略 $\pi$ 是一个神经网络,将状态映射到技能先验变化中的向量 g,在转换为潜在技能 Z。
然后解码器根据技能范围 H 的当前状态顺序重构动作。同时有一个底层残差策略,调整解码后的技能。
1.3 总结
该方法是一种基于技能的强化学习方法。
- 数据收集:使用最基本的控制器生成一些基本任务轨迹(移动、抓取),然后将这些轨迹分割成固定长度的序列,每一小段包括动作和对应的状态。
- 学习技能空间,使用变分自编码器将技能编码到潜在空间中;使用realNVP将技能潜在空间+机器人状态空间映射到简单分布空间(高斯分布),这样可以直接根据状态采样技能,称为技能先验。
- 强化学习:使用一个高层策略网络,根据当前的状态生成一个向量,根据技能先验(与当前状态有关的技能)中选择一个技能,利用技能解码器解码成机器人动作。
二、代码复现
2.1 环境搭建
(1)安装mujoco:
下载mujoco
1 | wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz |
创建一个隐藏文件夹,尽量不要修改此路经
1 | mkdir ~/.mujoco |
将mujoco库解压到上面的文件夹中
1 | tar -xvzf mujoco210-linux-x86_64.tar.gz -C ~/.mujoco |
编辑环境变量
1 | gedit ~/.bashrc |
在文件最后添加下面的语句,注意修改自己的用户名
1 | Mujoco environment |
刷新环境变量,重启terminal或执行下面的命令
1 | source ~/.bashrc |
测试mujoco
1 | cd ~/.mujoco/mujoco210/bin |
能看到一个mujoco界面启动,并看到一个二自由度机械臂,说明安装成功。../model/下也有很多其它的模型示例,感兴趣可以看看。
(2)python环境构建
1 | git clone https://github.com/krishanrana/reskill.git |
2.2 数据收集
使用下面的脚本收集数据
1 | python data/collect_demos.py --num_trajectories 40000 --subseq_len 10 --task block |
其中task可以设置为block或hook。
2.3 训练
训练技能模块:
1 | python train_skill_modules.py --config_file block/config.yaml --dataset_name fetch_block_40000 |
可视化训练完成的技能模块的性能:
1 | python utils/test_skill_modules.py --dataset_name fetch_block_40000 --task block --use_skill_prior True |
训练reskill代理:
1 | python train_reskill_agent.py --config_file block/config.yaml --dataset_name fetch_block_40000 |
可视化训练完成的reskill代理:
1 | python utils/test_reskill_agent.py --dataset_name fetch_block_40000 --env_name FetchSlipperyPush-v0 |
2.4 日志记录
使用W&B,第一次train时输入自己的api即可。
三、代码理解
3.1 基本定义
(1)机器人动作
算法中机器人通过下面的方法进行定义:
1 | def _set_action(self, action): |
可以看出在本算法中,机器人的动作被定义为了长度为4的数组,四个值分别代表机器人末端的控制位置和夹爪开合大小。(这里旋转被忽略了,因为任务是抓取方块到指定位置,所以算法直接设置末端永远竖直向下)
1 | action = [x, y, z, gripper] |
实际上gym中机器人的action使用长度为9的数组进行控制,分别代表末端的空间位置3个变量,末端的空间姿态四元数,夹爪两个平行板的动作。
1 | action = [x, y, z, quat1, quat2, quat3, quat4, gripper_l, gripper_r] |
(2)观测状态
观测状态通过如下代码获取:
1 | def _get_obs(self): |
可以看出观测状态是一个字典:
| 键 | 值 | 含义 |
|---|---|---|
| observation | [grip_x, grip_y, grip_z, | grip_pos,末端位置 |
| grip_q1, grip_q2, grip_q3, grip_q4, | grip_quat,末端姿态 | |
| gripper_left, gripper_right, | gripper_state,夹爪两侧状态 | |
| grip_vx, grip_vy, grip_vz, | grip_vel,末端速度 | |
| grip_wx, grip_wy, grip_wz | grip_w,末端角速度 | |
| gripper_vl, gripper_vr, | gripper_vel,夹爪两侧速度 | |
| obj1_x, obj1_y, obj1_z, | obj_i_pos,方块 i 位置 | |
| obj1_q1, obj1_q2, obj1_q3, obj1_q4 | obj_i_quat,方块 i 姿态 | |
| obj1_rx, obj1_ry, obj1_rz, | obj_i_rel_pos,方块 i 相对末端位置 | |
| obj1_rq1, obj1_rq2, obj1_rq3, obj1_rq4 | obj_i_rel_quat,方块 i 相对末端姿态 | |
| obj1_vx, obj1_vy, obj1_vz, | obj_i_velp, 方块 i 相对末端速度 | |
| obj1_wx, obj1_wy, obj1_wz, | obj_i_wp,方块 i 相对末端角速度 | |
| obj2… | 方块 2 位置、相对位置、相对速度 | |
| obji…] | 方块 i 位置、相对位置、相对速度 | |
| achieved_goal | [obj1_x, obj1_y, obj1_z, obj1_q1, obj1_q2, obj1_q3, obj1_q4, … |
每调用一次_get_obs()方法 保存所有方块的位置姿态 |
| grip_x, grip_y, grip_z, grip_q1, grip_q2, grip_q3, grip_q4 …] |
将当前末端位置 添加到 achieved_goal 最后 |
|
| desired_goal | [[x1, y1, z1], [x2, y2, z2], … ] | 多个目标位置 |
| force_sensor | [f_x, f_y, f_z] | force_reading,末端力,默认[0,0,0] |
💰
 微信支付
微信支付 支付宝
支付宝